chatgpt開發代碼 【第2966期】云音樂低代碼 + ChatGPT 實踐方案與思考
前言
AI 結合業務的研發chatgpt開發代碼,后續會逐漸增多了,會是一種趨勢么?今日前端早讀課文章由 @景莊分享,公號:云音樂技術團隊授權。
正文從這開始~~
隨著大語言模型(LLM)不斷涌現的各種能力,生成式 AI 的應用場景變得越來越廣闊。諸如 這類大語言模型在生成代碼方面非常的高效,因此對于如何將 LLM 的能力與低代碼產品進行結合,業界已經有了很多的討論和實踐,但都距離實際的生產場景有一定的距離。本文將會介紹的是,網易云音樂大前端團隊是如何借助 LLM 的能力來擴展和增強低代碼產品的研發體驗的,本文所涉及的內容均已在我們的內部生產環境中上線并得到應用。
功能預覽
首先,給大家快速地預覽一下我們在網易云音樂內部的低代碼平臺中上線的 AI 功能,目前提供了包括智能創建頁面、智能修改頁面、智能屬性配置、智能代碼片段生成、智能問答和編程助手等多種能力,下面是具體的演示內容。
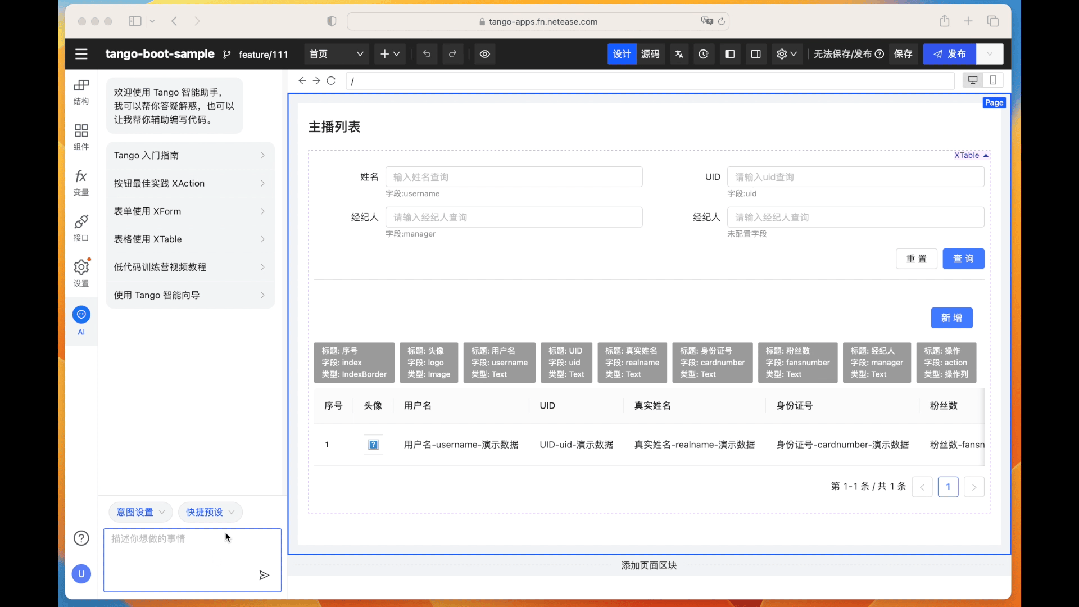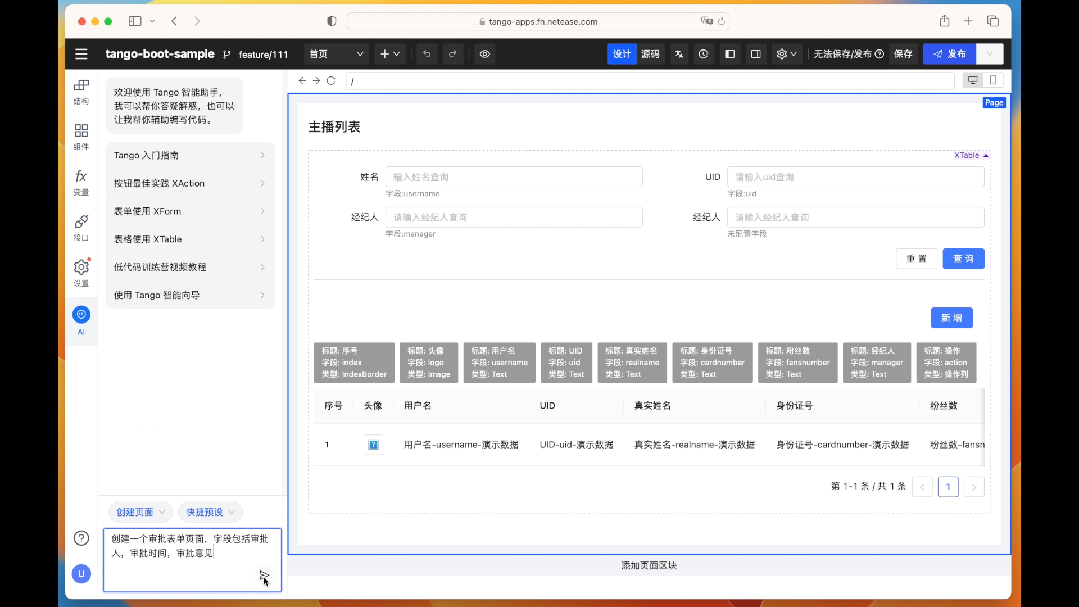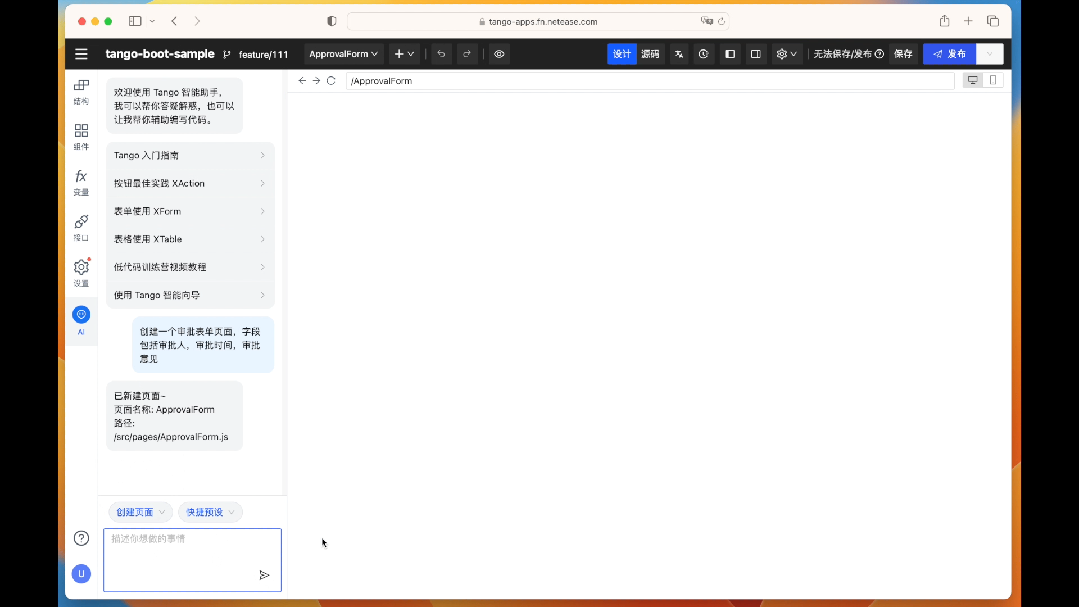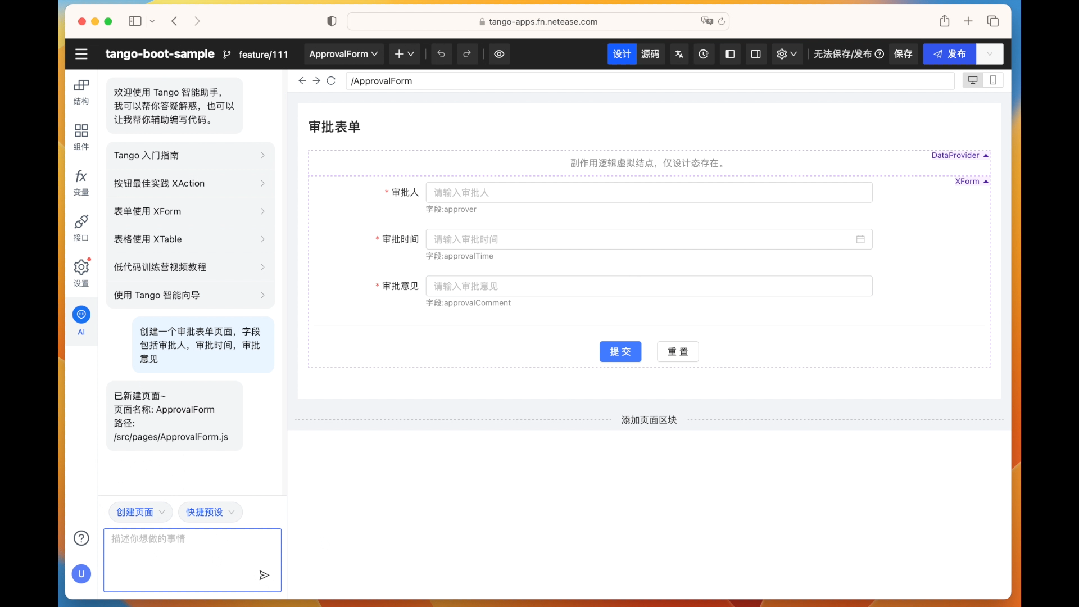
智能創建頁面
在云音樂低代碼平臺 中,我們集成了 LLM 的能力來加速前端應用的開發流程和體驗,開發者可以借助于簡單的自然語言描述的方式快速生成表單、表格、詳情、儀表盤等頁面,而無需記憶大量的組件配置和功能點,有效地提升了低代碼平臺的使用效率。
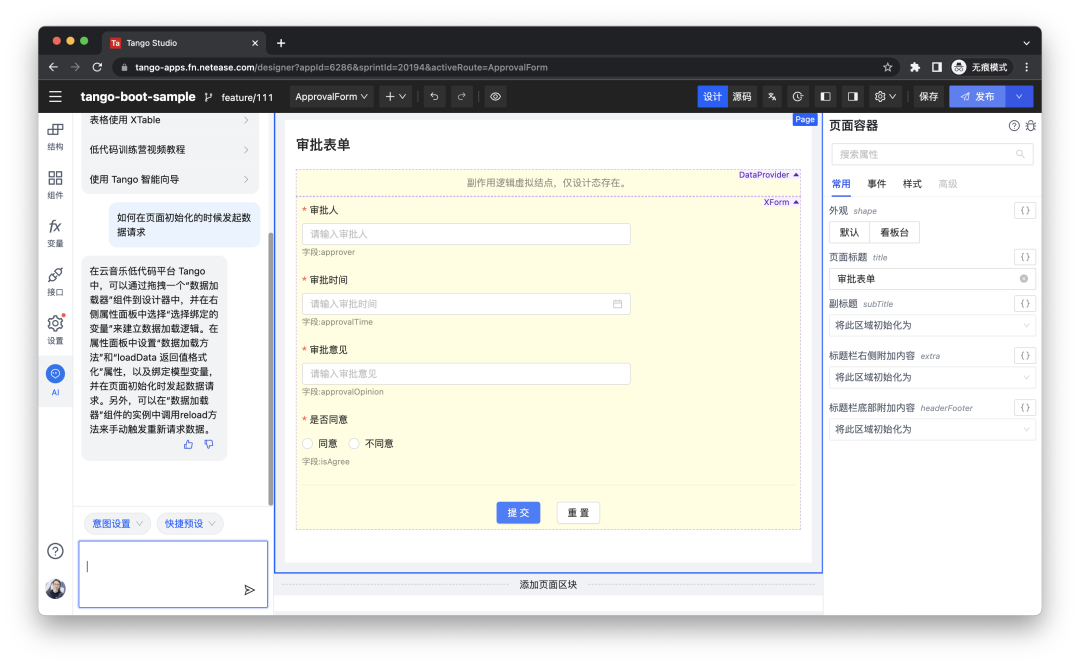
例如,在 AI 對話面板中,可以輸入 “創建一個審批表單頁面,字段包括審批人,審批時間,審批意見”,短暫的等待,就可以直接生成整個表單應用,用戶只需要進行邏輯上的微調,即可完成整個前端應用的構建。
page
智能修改頁面
如果生成的頁面不是你想要的,也可以通過聊天面板通過自然語言輸入的方式對頁面內容進行微調,例如增刪改表單或列表的字段,修改頁面標題,自定義組件樣式等等,為用戶提供低成本高容錯的交互體驗。
例如,“增加一個是否同意的字段”。

page
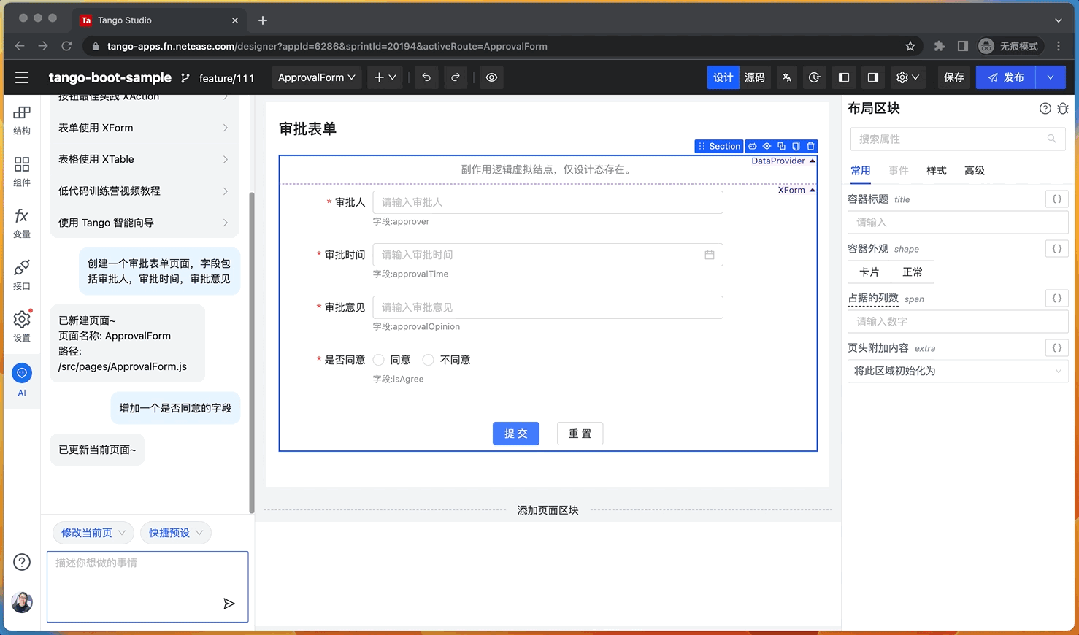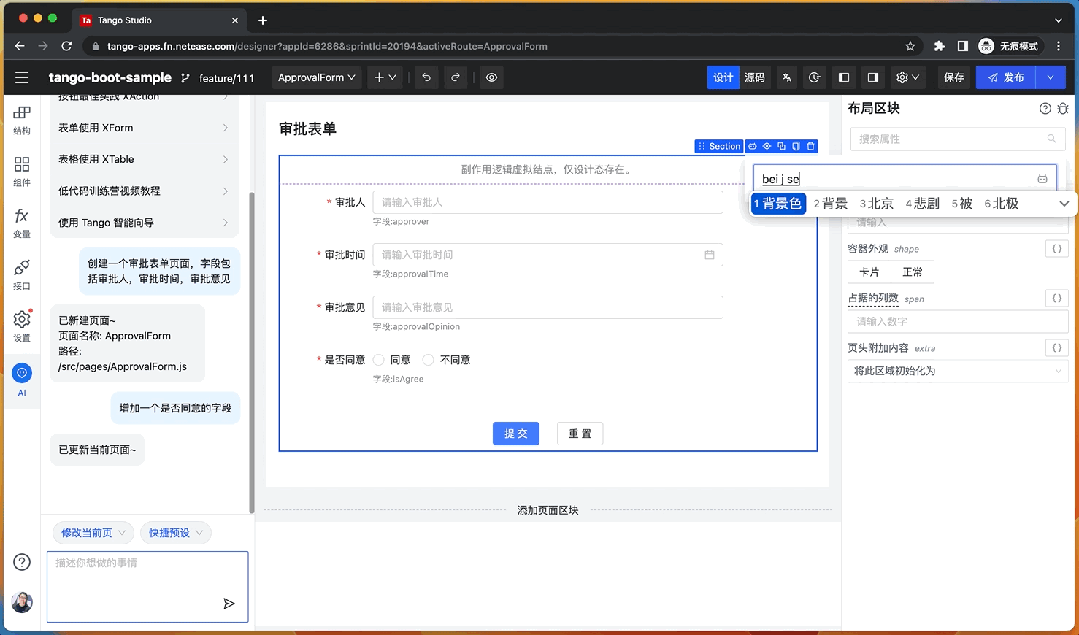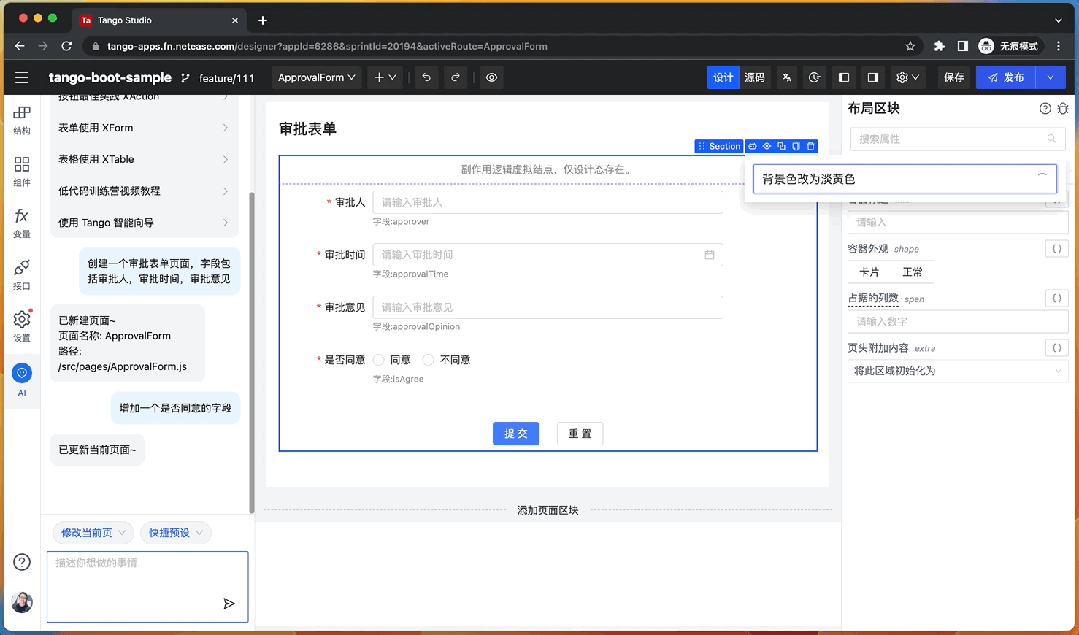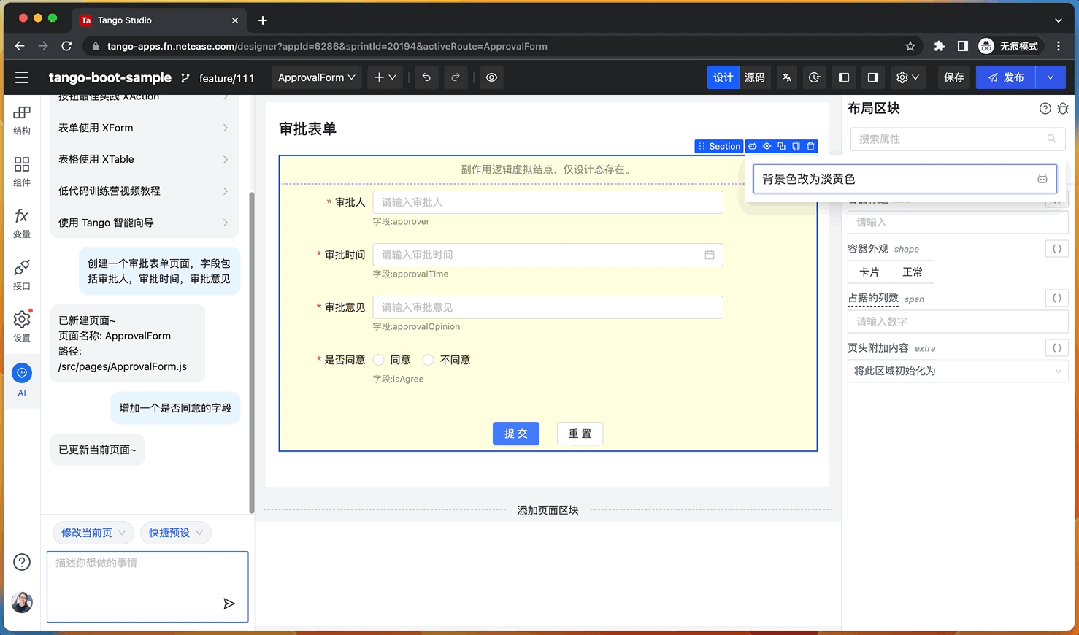
智能組件屬性配置
除了使用 AI 對話面板,用戶還在在選中某個組件后快速喚起 AI 輸入框,通過簡單的自然語言描述方式對當前組件的配置進行微調,例如組件的樣式,大小,狀態等屬性的設置。
例如,“背景色改為淡黃色”,“使用垂直布局” 等。
set

form
智能代碼片段生成
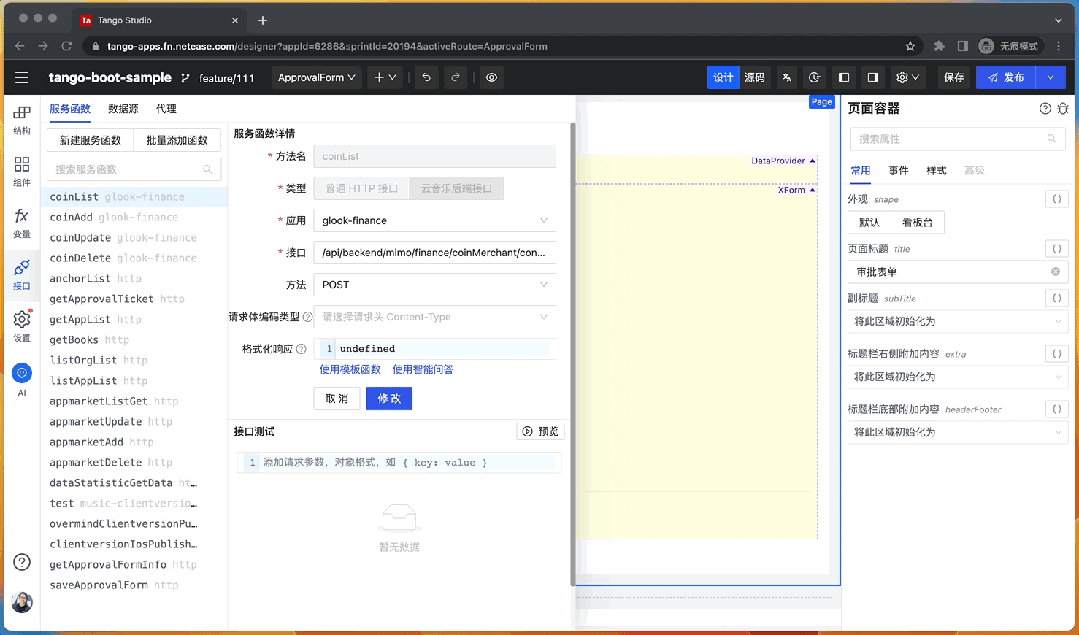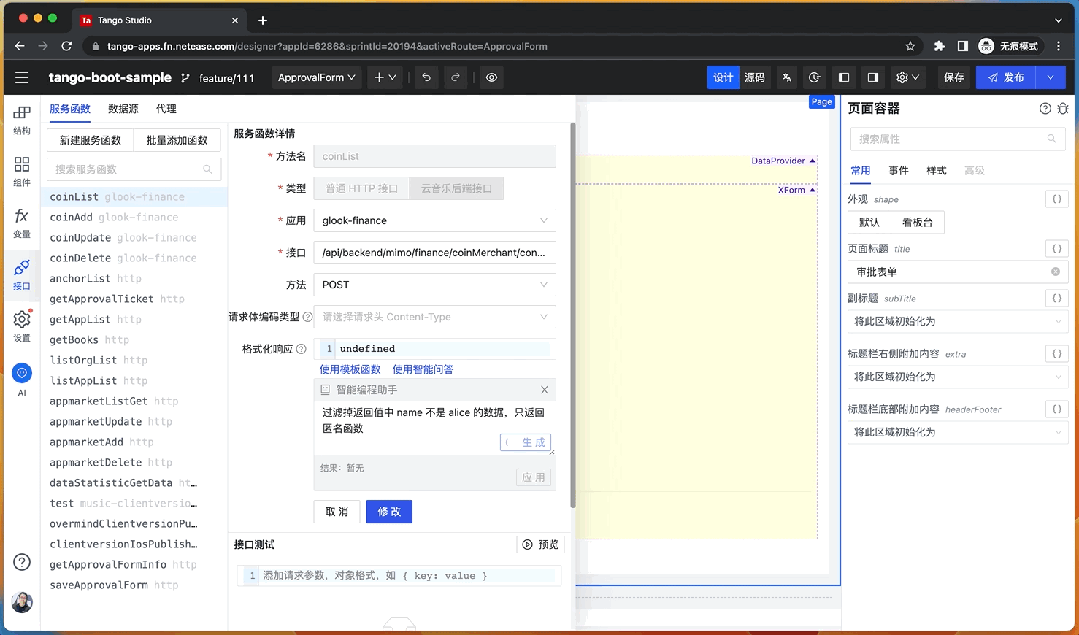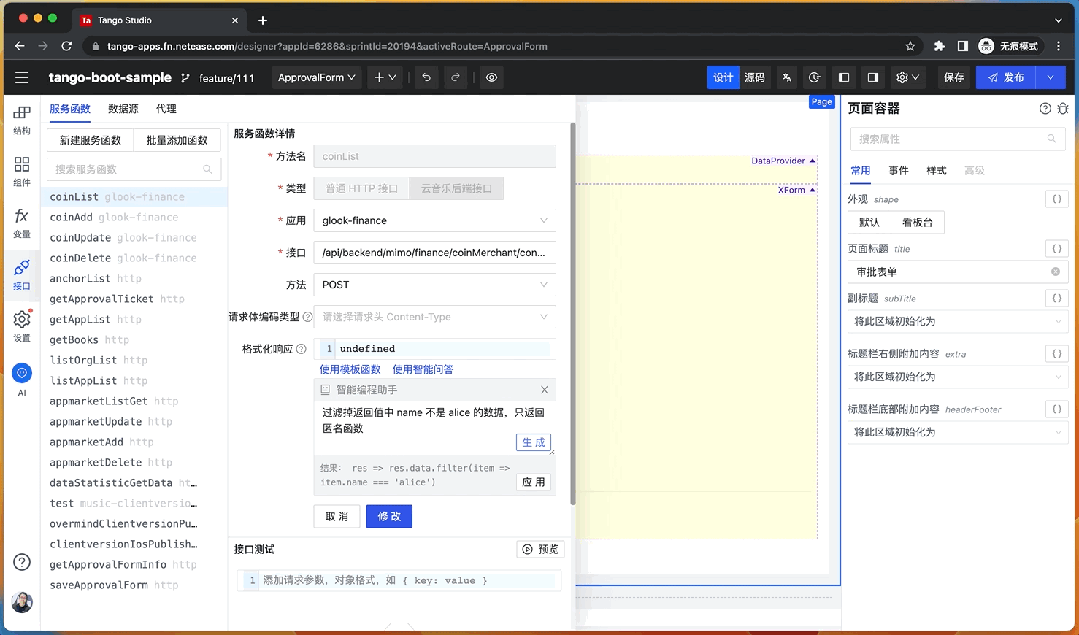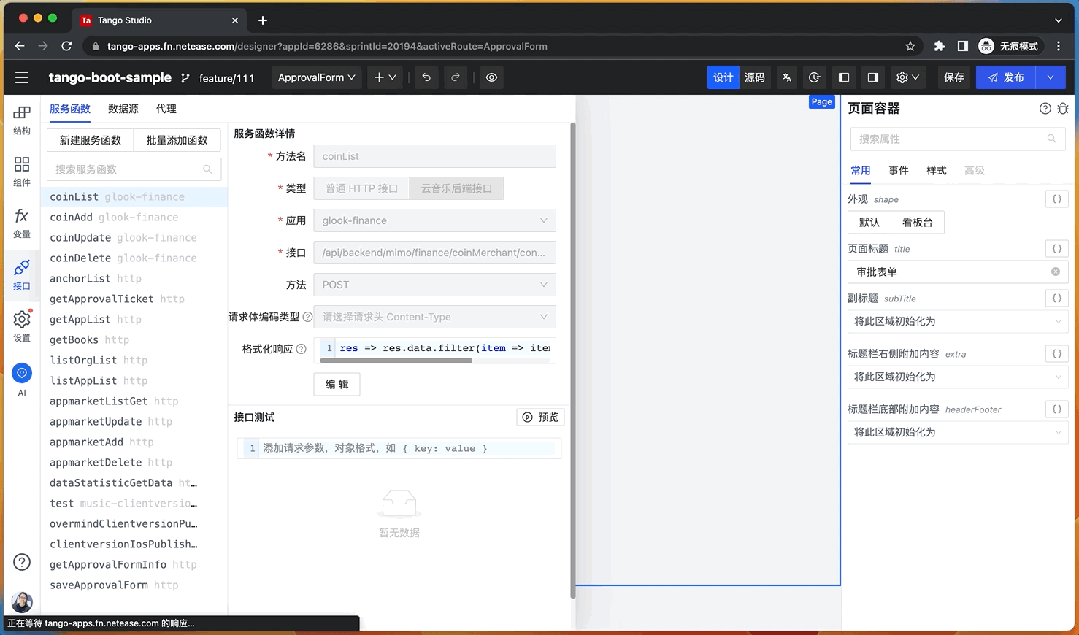
在云音樂低代碼平臺中,用戶有很多地方可以直接編寫代碼而不是使用可視化 UI,因此我們將 LLM 生成代碼的能力集成進來,幫助用戶快捷的編寫表達式代碼,為開發者提供比可視化拖拽更高效的研發體驗。
例如,“過濾掉返回值中 name 不是 的數據”。
code
智能問答和編程助手
由于 B 端產品的特殊性,通常會有一定復雜度的流程和功能模塊,用戶需要閱讀使用文檔才能完全掌握系統的使用。借助 LLM 的能力,我們可以將軟件文檔分片后存儲到向量數據庫,并借助 LLM 來構建基于上下文的問答系統,為用戶提供全新的問答體驗。同樣,我們將這種能力融入到系統的問答過程中,為用戶提供比關鍵詞搜索更良好的答疑體驗。
Q&A
構建思路與實現原理
此前曾經分享過對于,結合業務和團隊的現狀和痛點,我們團隊構建了一套基于源碼的低代碼研發體系,支持開發者使用 和 雙模式在線混合開發,并且支持兩者的雙向同步,為業務場景提供足夠的靈活性,借此推動低代碼研發方式在云音樂大前端場景的漸進式覆蓋。
云音樂低代碼平臺實現的核心思路是:將源代碼解析為 AST ,在 AST 的基礎上進一步抽象和建立 文件模型 和 節點模型,通過將視圖的拖拽配置行為轉為對 AST 的操縱和修改,進而將變化后的 AST 重新還原為源代碼。具體如下圖所示。
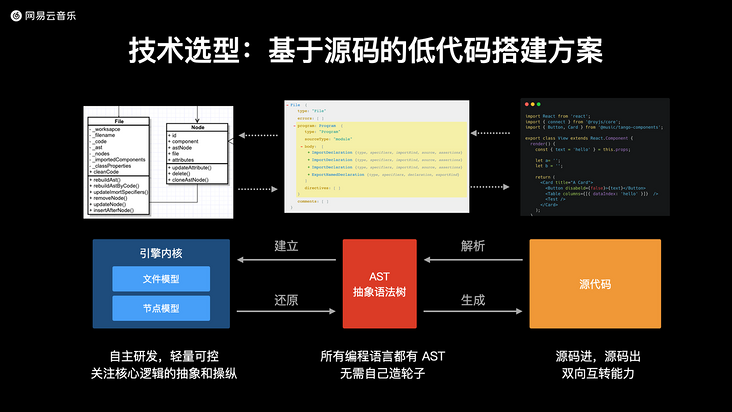
以源碼為核心的低代碼平臺構建方案為我們在內部大力推廣低代碼開發提供了很大的便利,因為在實際的使用過程中,大量的需求變化仍然依賴于開發者對組件和邏輯的自定義,傳統的低代碼方案對于這種需求變化的支持并不友好,而以源碼為核心的低代碼平臺則可以很好的解決這個問題。
此外,以 GPT 為代表的這類大語言模型在文本生成方面具有非常高的效率,因此將其應用在代碼生成方面具有非常高的準確性。結合我們在云音樂采用的源碼驅動的低代碼開發方案,我們很順利的將 GPT 的能力集成到了云音樂低代碼平臺中。
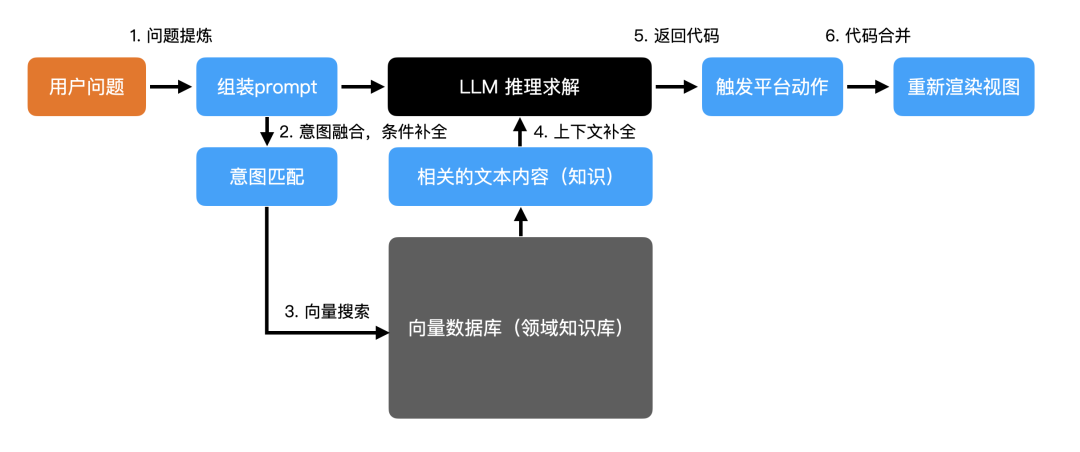
具體的原理如圖所示,對于用戶的輸入指令,首先會被組裝為標準化的 模版,進而解析用戶指令中的用戶意圖,借助于向量數據庫進行近似度匹配,將關聯的信息合并到 中,然后借助預訓練的 GPT 大模型推理生成代碼,最后將 GPT 返回的代碼合并到當前工程中,觸發應用視圖重新渲染。
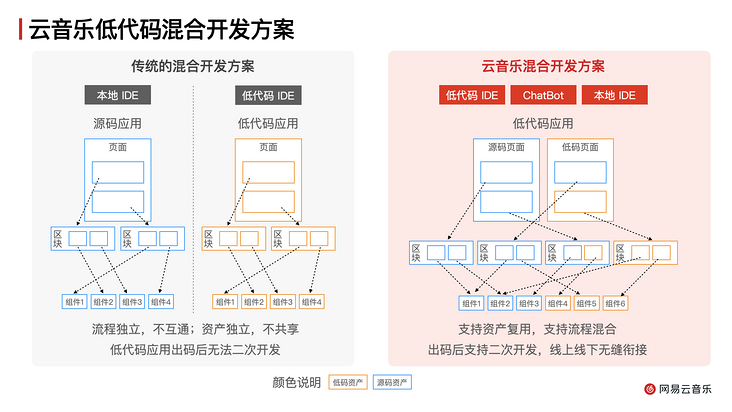
通過構建基于源碼的低代碼開發能力,可以為一線業務開發同學提供全新的線上線下一體化混合開發流程。傳統的實現方案線上與線下流程獨立,不互通;資產獨立,不共享;并且低代碼應用出碼流程也是單向不可回流的。結合于大語言模型的能力,我們進一步構建了云音樂的混合開發方案,支持使用同一份前端資產和代碼庫,支持用戶通過低代碼 IDE、、本地 IDE 三種方式開發同一個前端工程。具體的效果如下圖所示。
從編程語言到提示工程( )
在云音樂低代碼平臺中,我們將自然語言推理作為一個獨立的底層服務。在用戶輸入指令后,會將用戶的輸入指令和當前工程的信息組裝為一個標準化的 模版,然后將 模版發送給自然語言推理服務,并基于底層大語言模型服務推理生成代碼,進而再將生成的代碼合并到當前工程中。使用提示工程進行低代碼編程的基本流程如下圖所示。
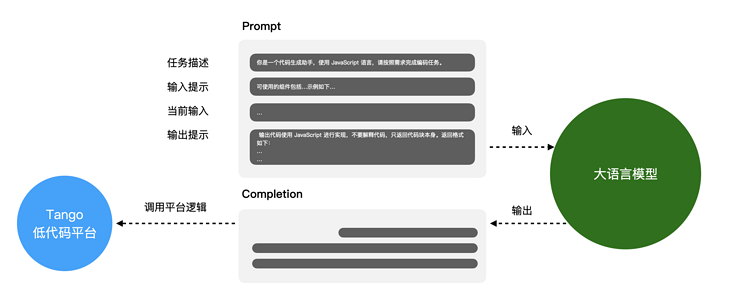
圖:借助提示工程實現低代碼編程的基本流程示意圖
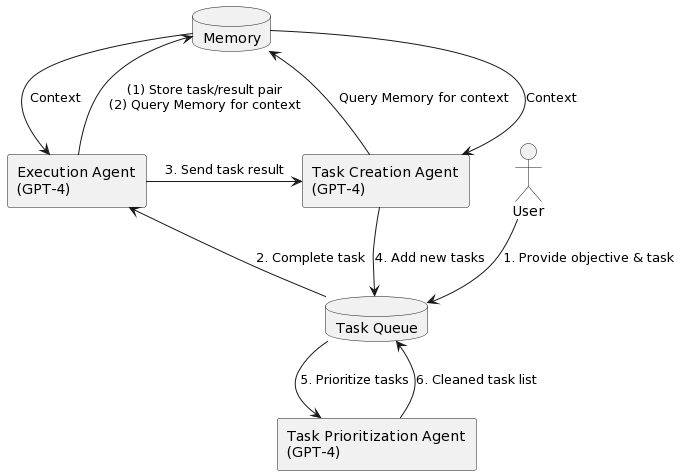
可以說提示工程已經成為了一種新型的平民化編程語言,借助于大語言模型的能力,可以低成本的實現代碼的生成。類似于 , Self- 這類產品,則是直接基于結構化的 來驅動 GPT 實現自動任務調度。 使用 GPT-4 生成、優先排序和執行任務,使用插件進行互聯網瀏覽和其他訪問操作。它使用外部內存來跟蹤自己正在做什么并提供上下文,這使得它能夠評估自己的情況、生成新任務或自我糾正,并將新任務添加到隊列中,然后對其進行優先排序,具體的流程如下圖所示。
編程語言的平民化
我認為,以 GPT 為代表的大模型服務必將改變未來所有產品的構建思路和用戶使用方式,LLM 也將成為新一代的互聯網基礎設施。借助于生成式 AI 的能力,可以顯著的改善低代碼產品的可用性和易用性問題,并且讓軟件開發的過程更加簡單且富有趣味性。
同時也不得不讓我們重新思考低代碼產品的設計與構建過程,因為 GPT 為代表的這類生成式 AI 在代碼編寫方面尤為擅長,它將顯著的提升編程語言的平民化速度。相較于編程語言,自然語言具有更高的容錯性,而傳統的代碼編程則非常依賴于精準的使用編程語法。在 中,你甚至可以利用偽代碼進行編程。

圖:使用 進行偽代碼編程
對未來的思考
對于低代碼產品而言,私有協議和復雜的 DSL 設計會導致系統的可擴展性變得越發艱難,且難以利用社區龐大的開源代碼資產。而 GPT 這類大語言模型利用了數量龐大的開源數據集進行訓練,在生成主流編程語言代碼方面具比一般程序員更強的編程能力,如果能夠將 LLM 的能力與低代碼的能力相結合,將會極大的降低軟件系統的開發成本。因此,系統的設計需要考慮主流的社區生態和方案chatgpt開發代碼,否則將很難具有持續性。因此,更加明智的選擇是擁抱開源社區的主流生態,最大化的利用開源資產和公司內部資產的結合來提升產品的功能和體驗。
此外,借助于大語言模型能力的能力chatgpt開發代碼,我們也需要重新思考軟件交互界面的設計,自然語言界面將會成為新的人機交互的必備界面。對于低代碼產品的構建而言,過度的可視化交互邏輯反而會增加系統的復雜度,諸如 這類低代碼產品也在越來越強調邏輯表達的靈活性,某些情況下圖形界面并不比少量的表達式代碼更高效。對于產品構建而言,需要找準目標用戶,為用戶提供更加符合直覺和心智的產品。
最后,以 為代表的生成式 AI 可以大大提高信息處理和決策的效率,將會對我們對工作和生活帶來深刻的影響,身處其中,我們需要不斷探索和應用這些新的變化。
關于本文
免責聲明:本文系轉載,版權歸原作者所有;旨在傳遞信息,不代表本站的觀點和立場和對其真實性負責。如需轉載,請聯系原作者。如果來源標注有誤或侵犯了您的合法權益或者其他問題不想在本站發布,來信即刪。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。