chatGPT模型參數(shù) 從語(yǔ)言模型到ChatGPT:大型語(yǔ)言模型的發(fā)展和應(yīng)用(一)

前言
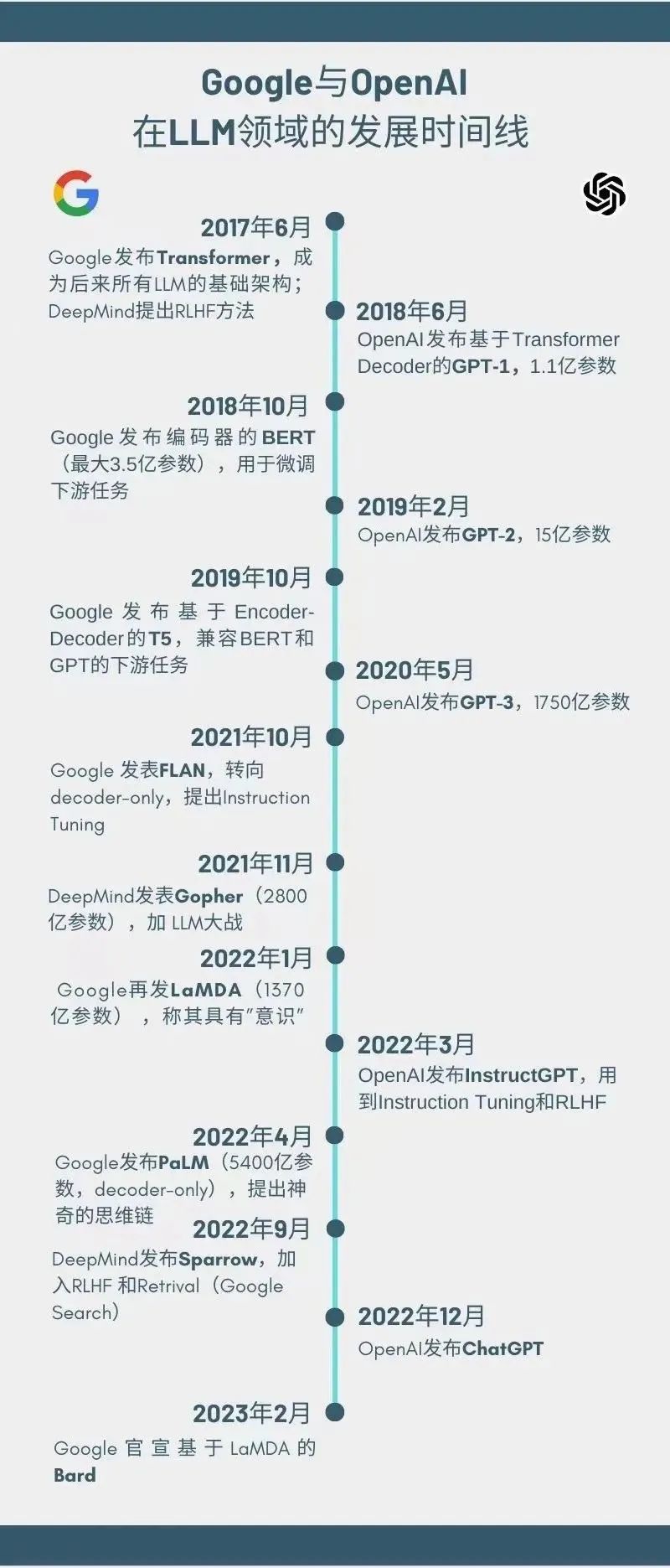
大型語(yǔ)言模型(LLM)是指能夠處理大量自然語(yǔ)言數(shù)據(jù)的深度學(xué)習(xí)模型,它已經(jīng)在自然語(yǔ)言處理、文本生成、機(jī)器翻譯等多個(gè)領(lǐng)域中展現(xiàn)出了巨大的潛力。在過(guò)去幾年中,LLM領(lǐng)域經(jīng)歷了飛速的發(fā)展,其中和作為兩家領(lǐng)先的公司在這個(gè)領(lǐng)域中的表現(xiàn)備受關(guān)注。
是LLM領(lǐng)域的重要參與者,其BERT自編碼模型和T5編碼解碼器在自然語(yǔ)言理解任務(wù)上取得了優(yōu)異的表現(xiàn)。BERT模型通過(guò)預(yù)訓(xùn)練大規(guī)模文本數(shù)據(jù),提取出詞向量的同時(shí),也能夠?qū)W習(xí)到上下文信息。而T5模型則是在BERT的基礎(chǔ)上,進(jìn)一步將生成式任務(wù)融入其中,實(shí)現(xiàn)了一體化的自然語(yǔ)言處理能力。這些模型的出現(xiàn),極大地推動(dòng)了LLM領(lǐng)域的發(fā)展。
與之相反的是,則從2018年開(kāi)始,堅(jiān)持使用 only的GPT模型,踐行著「暴力美學(xué)」——以大模型的路徑,實(shí)現(xiàn)AGI。GPT模型通過(guò)預(yù)訓(xùn)練海量語(yǔ)料庫(kù)數(shù)據(jù),學(xué)習(xí)到了自然語(yǔ)言中的規(guī)律和模式,并在生成式任務(wù)中取得了出色的表現(xiàn)。堅(jiān)信,在模型規(guī)模達(dá)到足夠大的情況下,單純的模型就可以實(shí)現(xiàn)AGI的目標(biāo)。
除了和外,還有許多其他公司和研究機(jī)構(gòu)也在LLM領(lǐng)域做出了貢獻(xiàn)。例如,的模型、的 NLG模型等等。這些模型的不斷涌現(xiàn),為L(zhǎng)LM領(lǐng)域的發(fā)展注入了新的動(dòng)力。
如果只用解碼器的生成式是通用LLM的王道,2019年10月,同時(shí)押注編碼解碼器的T5,整整錯(cuò)失20個(gè)月,直到2021年10月發(fā)布FLAN才開(kāi)始重新轉(zhuǎn)變?yōu)?only。這表明,在實(shí)際應(yīng)用中,不同任務(wù)可能需要不同類(lèi)型的模型,而在特定任務(wù)中,編碼解碼器的結(jié)構(gòu)可能比-only模型更加適合。
本文將基于課件回顧大型語(yǔ)言模型的發(fā)展歷程,探討它們是如何從最初的基礎(chǔ)模型發(fā)展到今天的高級(jí)模型的,并介紹的發(fā)展歷程,看看如何實(shí)現(xiàn)彎道超車(chē)。
Zero-Shot (ZS) and Few-Shot (FS) In-
上下文學(xué)習(xí)(In- )
近年來(lái),語(yǔ)言模型越來(lái)越傾向于使用更大的模型和更多的數(shù)據(jù),如下圖所示,模型參數(shù)數(shù)量和訓(xùn)練數(shù)據(jù)量呈指數(shù)倍增加的趨勢(shì)。

模型名稱(chēng)
說(shuō)明
備注
GPT
with 12 [參數(shù)量117M]
on : over 7000 (4.6GB text).
表明大規(guī)模語(yǔ)言建模可以成為自然語(yǔ)言推理等下游任務(wù)的有效預(yù)訓(xùn)練技術(shù)。
GPT2
Same as GPT, just (117M -> 1.5B)
on much more data: 4GB -> 40GB of text data ()
涌現(xiàn)出優(yōu)異的Zero-shot能力。
GPT3
in size (1.5B -> 175B)
data (40GB -> over )
涌現(xiàn)出強(qiáng)大的上下文學(xué)習(xí)能力,但是在復(fù)雜、多步推理任務(wù)表現(xiàn)較差。
近年來(lái),隨著GPT模型參數(shù)量的增加,GPT2與GPT3模型已經(jīng)表現(xiàn)出了極佳的上下文學(xué)習(xí)能力(In- )。這種能力允許模型通過(guò)處理上下文信息來(lái)更好地理解和處理自然語(yǔ)言數(shù)據(jù)。GPT模型通過(guò)Zero-Shot、One-Shot和Few-Shot學(xué)習(xí)方法在許多自然語(yǔ)言處理任務(wù)中取得了顯著的成果。
其中,Zero-Shot學(xué)習(xí)是指模型在沒(méi)有針對(duì)特定任務(wù)進(jìn)行訓(xùn)練的情況下,可以通過(guò)給定的輸入和輸出規(guī)范來(lái)生成符合規(guī)范的輸出結(jié)果。這種方法可以在沒(méi)有充足樣本的情況下chatGPT模型參數(shù),快速生成需要的輸出結(jié)果。One-Shot和Few-Shot學(xué)習(xí)則是在樣本量較少的情況下,模型可以通過(guò)學(xué)習(xí)一小部分示例來(lái)完成相應(yīng)任務(wù),這使得模型能夠更好地應(yīng)對(duì)小樣本學(xué)習(xí)和零樣本學(xué)習(xí)的問(wèn)題。
上下文學(xué)習(xí)介紹
大模型有一個(gè)很重要的涌現(xiàn)能力( )就是In- (ICL),也是一種新的范式chatGPT模型參數(shù),指在不進(jìn)行參數(shù)更新的情況下,只在輸入中加入幾個(gè)示例就能讓模型進(jìn)行學(xué)習(xí)。下面給出ICL的公式定義:

其中,符號(hào)含義如下,從這些符號(hào)中也能看出影響ICL的因素:
I:具體任務(wù)的描述信息
x:輸入文本
y:標(biāo)簽
M:語(yǔ)言模型
C:闡述示例
f:打分函數(shù)
下面將開(kāi)始介紹如何提升模型的ICL能力。
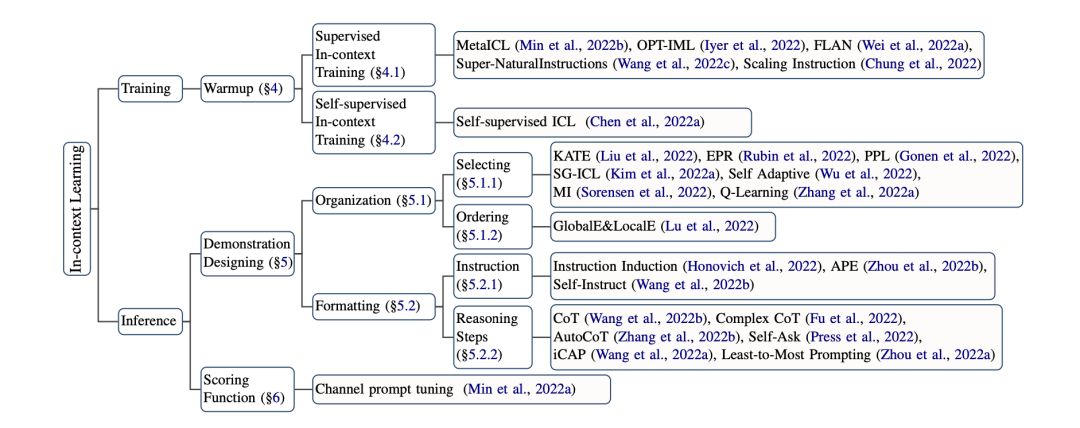
訓(xùn)練優(yōu)化ICL能力
有監(jiān)督訓(xùn)練:
在ICL格式的數(shù)據(jù)集上,進(jìn)行有監(jiān)督的訓(xùn)練。
就直接把很多任務(wù)整合成了ICL的形式精調(diào)模型,在52個(gè)數(shù)據(jù)集上取得了比肩直接精調(diào)的效果。另外還有部分研究專(zhuān)注于 ,構(gòu)建更好的任務(wù)描述讓模型去理解chatGPT模型參數(shù),而不是只給幾個(gè)例子(),比如-PT、FLAN。
自監(jiān)督訓(xùn)練:
將自然語(yǔ)言理解的任務(wù)轉(zhuǎn)為ICL的數(shù)據(jù)格式。

圖1代表不同自然語(yǔ)言理解任務(wù)轉(zhuǎn)為ICL的輸入輸出形式。
圖2表示訓(xùn)練樣本示例,包含幾個(gè)訓(xùn)練樣本,前面的樣本作為后面樣本的任務(wù)闡述。
推理優(yōu)化ICL能力
設(shè)計(jì)
樣本選取:文本表示、互信息選擇相近的;選取;語(yǔ)言模型生成……
樣本排序:距離度量;信息熵……
任務(wù)指示:APE語(yǔ)言模型自動(dòng)生成
推理步驟:COT、多步驟ICL、Self-Ask
打分函數(shù)
:直接取條件概率P(y|x),缺點(diǎn)在于y必須緊跟在輸入的后面;
:再用語(yǔ)言模型過(guò)一遍句子,這種方法可以解決上述固定模式的問(wèn)題,但計(jì)算量增加了;
:評(píng)估P(x|y)的條件概率(用貝葉斯推一下),這種方法在不平衡數(shù)據(jù)下表現(xiàn)較好。
影響ICL表現(xiàn)的因素
預(yù)訓(xùn)練語(yǔ)料的多樣性比數(shù)量更重要,增加多種來(lái)源的數(shù)據(jù)可能會(huì)提升ICL表現(xiàn);
用下游任務(wù)的數(shù)據(jù)預(yù)訓(xùn)練不一定能提升ICL表現(xiàn),并且PPL更低的模型也不一定表現(xiàn)更好;
當(dāng)LM到達(dá)一定規(guī)模的預(yù)訓(xùn)練步數(shù)、尺寸后,會(huì)涌現(xiàn)出ICL能力,且ICL效果跟參數(shù)量正相關(guān)。
免責(zé)聲明:本文系轉(zhuǎn)載,版權(quán)歸原作者所有;旨在傳遞信息,不代表本站的觀(guān)點(diǎn)和立場(chǎng)和對(duì)其真實(shí)性負(fù)責(zé)。如需轉(zhuǎn)載,請(qǐng)聯(lián)系原作者。如果來(lái)源標(biāo)注有誤或侵犯了您的合法權(quán)益或者其他問(wèn)題不想在本站發(fā)布,來(lái)信即刪。
聲明:本站所有文章資源內(nèi)容,如無(wú)特殊說(shuō)明或標(biāo)注,均為采集網(wǎng)絡(luò)資源。如若本站內(nèi)容侵犯了原著者的合法權(quán)益,可聯(lián)系本站刪除。