老鹿學(xué)Ai繪畫(huà):三種方法制作文字融入圖片

今天我們要分享的內(nèi)容視頻版如下,視頻已添加進(jìn)度條及配音,想要原視頻以及模型的鹿友后臺(tái)撩我獲取:
視頻版稍后單獨(dú)發(fā)送
以下是圖文版內(nèi)容:
正文共:3267字 45圖
預(yù)計(jì)閱讀時(shí)間:9分鐘
今天要分享的內(nèi)容是最近很火的這種文字融入圖片效果:
這個(gè)效果當(dāng)時(shí)看到群里發(fā)出來(lái)的時(shí)候,我正在川西旅游,本想著回來(lái)之后試試寫(xiě)一下,結(jié)果回來(lái)之后發(fā)現(xiàn)網(wǎng)上已經(jīng)有教程了:
后來(lái)又一直很忙,一直拖到現(xiàn)在快一個(gè)月了,還是寫(xiě)一下吧,算是個(gè)了結(jié)。
我這里總結(jié)了三種方法,前兩種方法網(wǎng)上已經(jīng)有很多教程了,最后一種方法是我自己研究的,不太好,也算是一種思路吧!
好了,廢話不多說(shuō),讓我們看看如何制作這種文字融入圖片的效果吧!
01
前言及準(zhǔn)備工作
雖說(shuō)是三種方法,其實(shí)大體思路都差不多,都需要借助SD的,只不過(guò)用到的模型不一樣。
前兩種方法文生圖和圖生圖都可以,最后一種只能用圖生圖,我這里就統(tǒng)一用圖生圖來(lái)演示吧。
首先我用文生圖生成了這樣三張夜景圖:
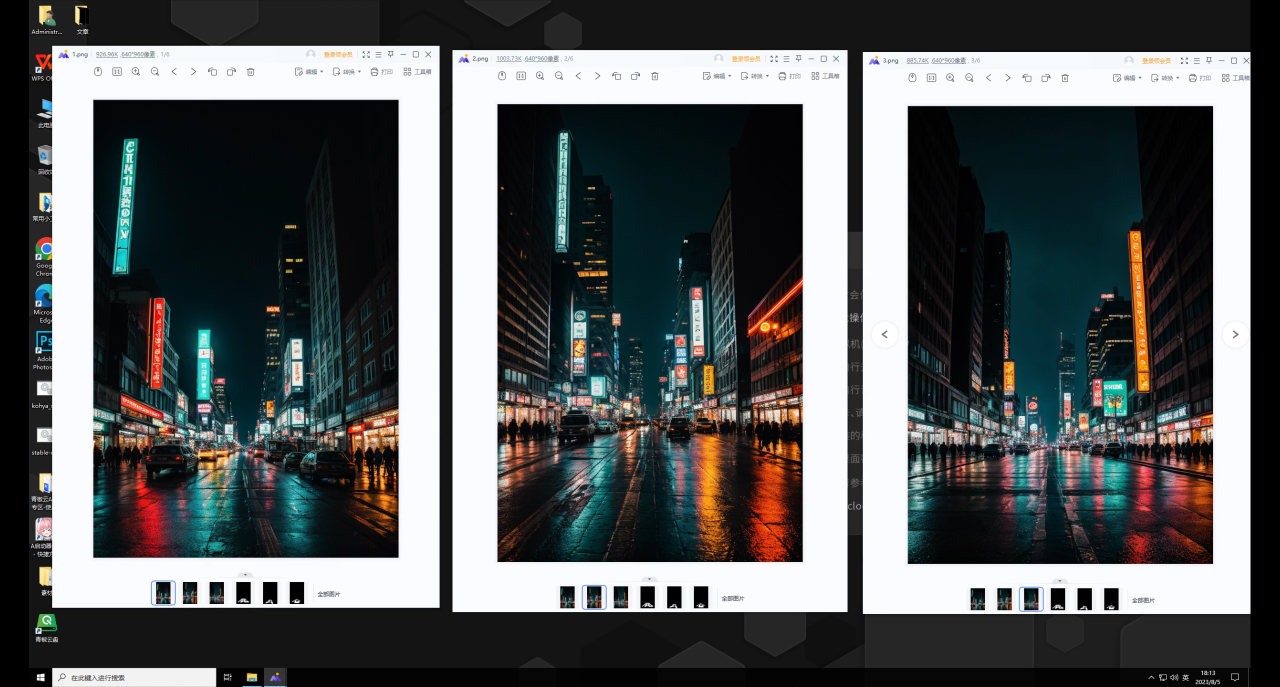
然后再用Ps制作了這樣三張黑底白色的文字圖,這里有兩點(diǎn)提醒大家一下,首先文字可以適當(dāng)高斯模糊一樣,這樣邊緣不會(huì)太銳利。
其次文字的構(gòu)圖最好要參考一下你要融入的圖片,特別是人物圖,否則可能需要頻抽卡才能得到比較滿意的效果。
我這里是夜景圖,就簡(jiǎn)單的把文字做了一下透視:

打開(kāi)SD,在圖片信息里載入夜景圖獲取它的提示詞信息,然后直接發(fā)送到圖生圖:
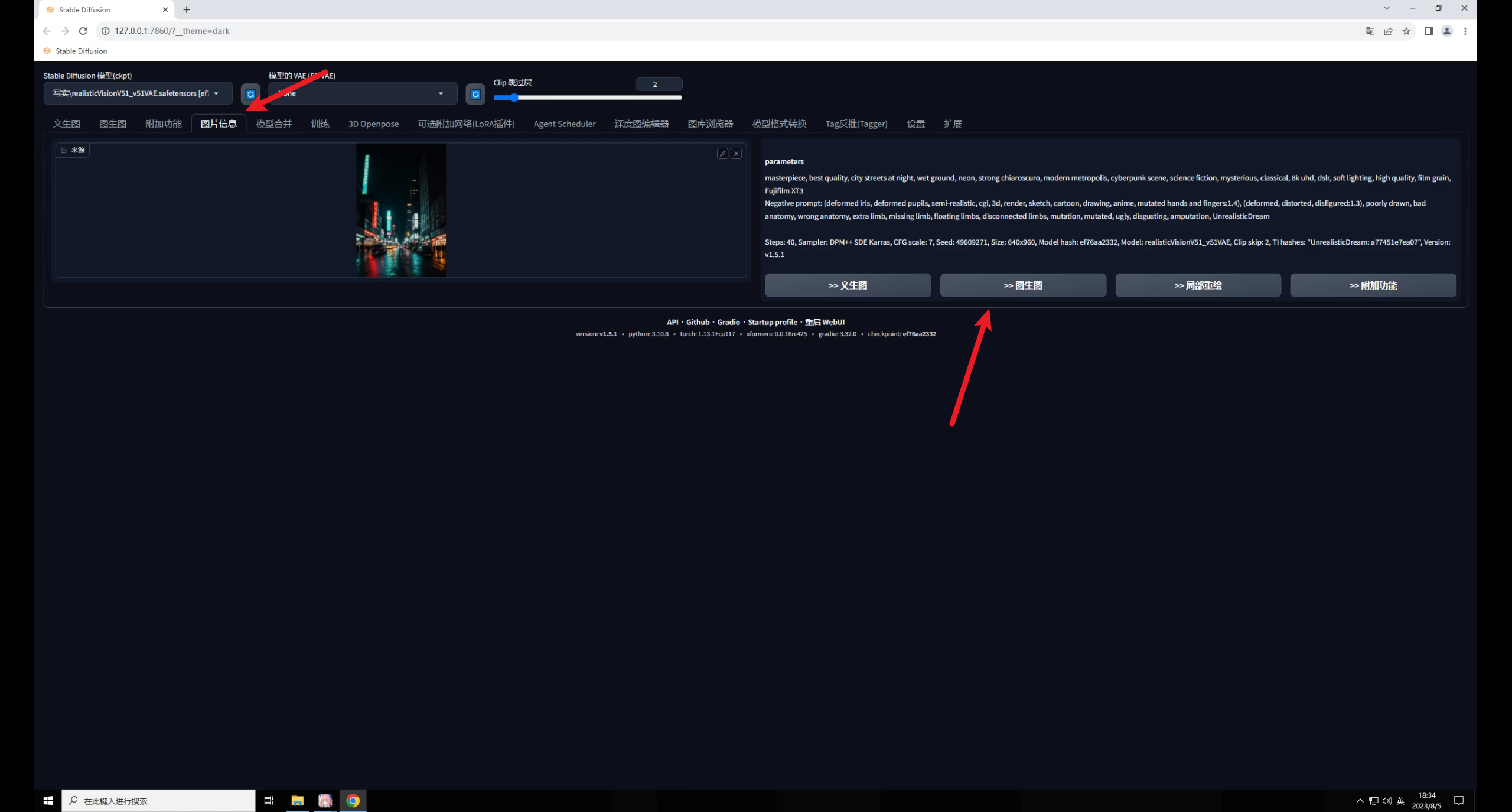
大模型我用的是 ,這是C站下載量最高的一款寫(xiě)實(shí)類模型,也是我最常用的一款,目前已經(jīng)更新到V5.1版本了:
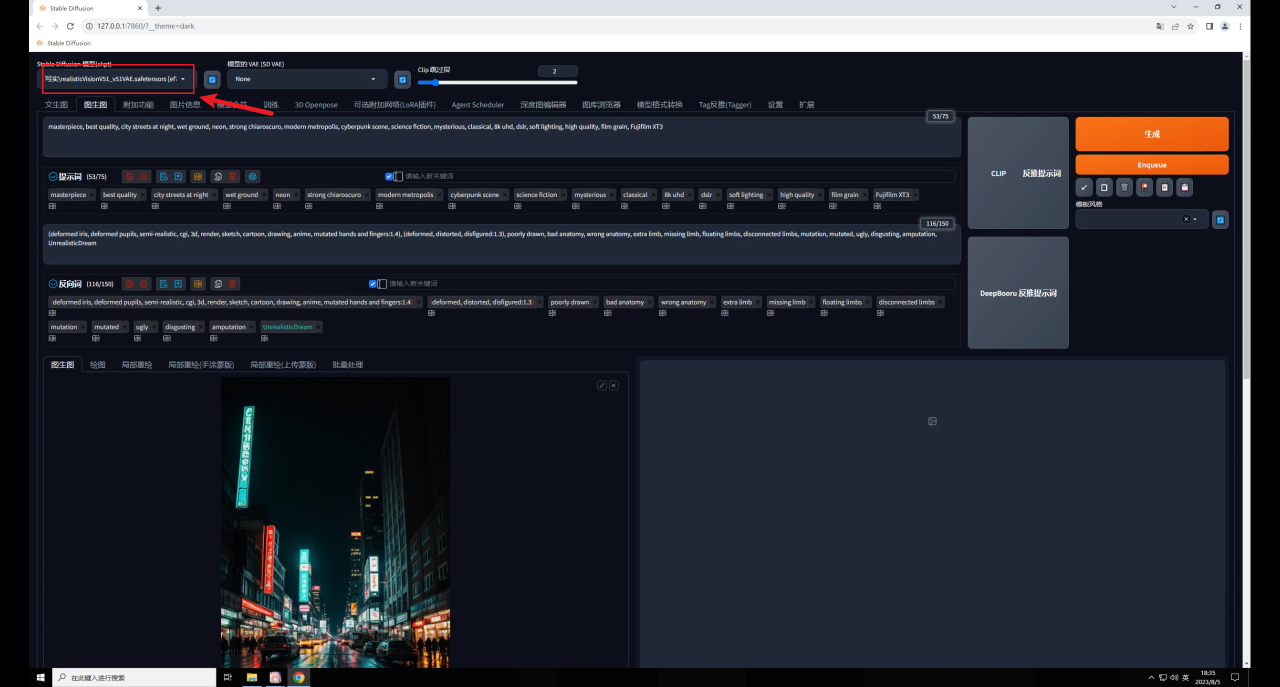
做這種效果有一定的隨機(jī)性,不要忘記保持隨機(jī)種子為-1,方便抽卡:

02
使用Tile模型制作
第一種方式是使用 Tile模型制作,這個(gè)是 1.1新增的一個(gè)模型。
模型以及預(yù)處理器在上一篇通用參數(shù)的文章中已經(jīng)分享給大家了,各位鹿友可以自行去獲取:

這個(gè)模型最大的特點(diǎn)是它會(huì)根據(jù)你在中輸入的圖片信息在原圖中繪制新的細(xì)節(jié)。
因此它通常用于放大圖像,后面的文章我也會(huì)給大家分享我在工作中常用的兩種批量放大圖片的方法:

回到SD中,先把文字圖拖進(jìn)里,勾選啟用和完美像素:
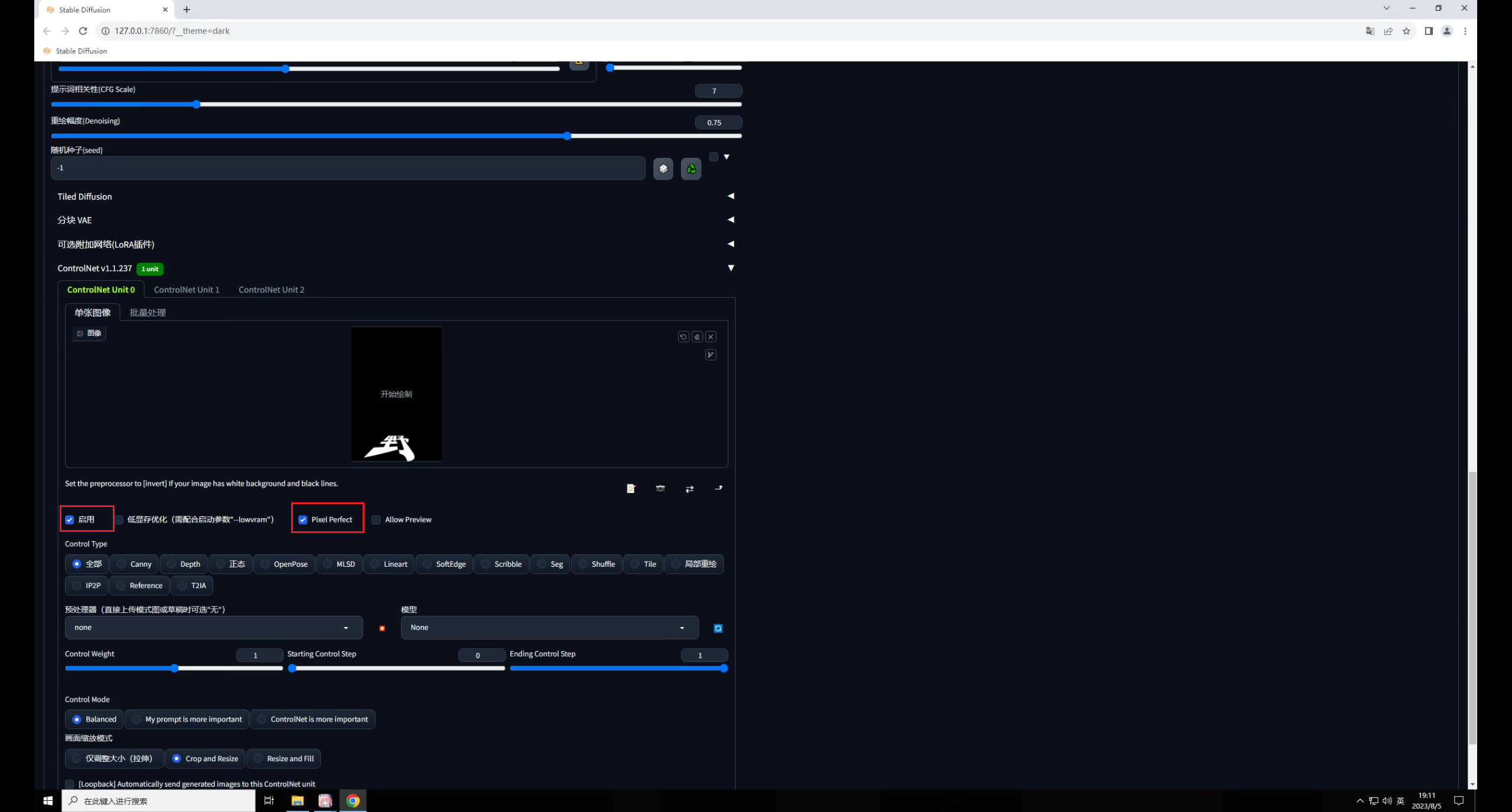
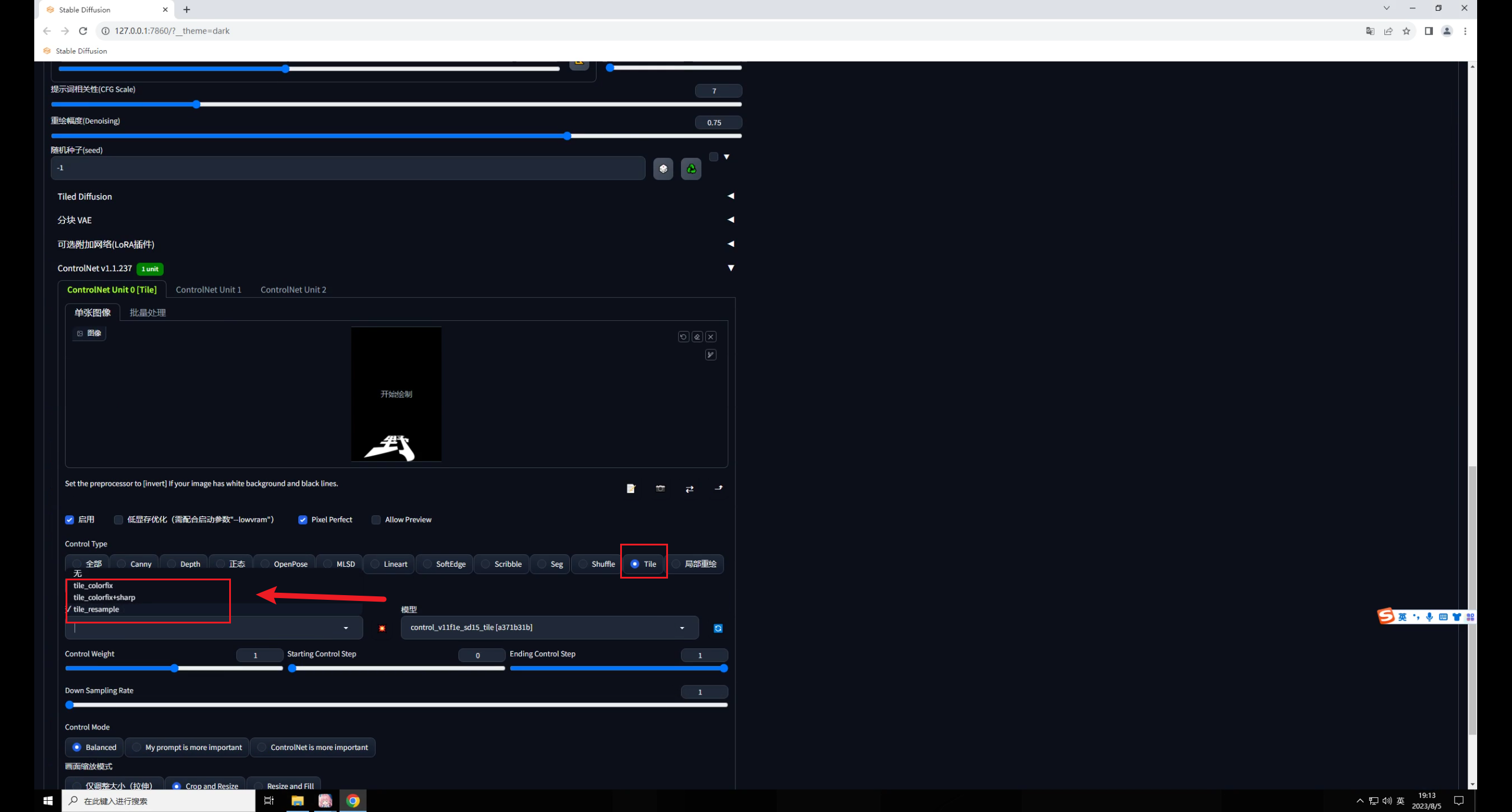
控制類型選擇Tile,這個(gè)模型有三種預(yù)處理,分別是顏色覆蓋、顏色覆蓋加銳化,重采樣。
前面兩種我測(cè)試過(guò),由于我們輸入的文字圖是黑底的,使用顏色覆蓋生成的圖像會(huì)很暗。
因此我們就選擇重采樣這種方式就好,爆炸圖標(biāo)點(diǎn)不點(diǎn)都沒(méi)關(guān)系:
先直接生成一張圖看看,你會(huì)發(fā)現(xiàn)文字過(guò)于清楚,畫(huà)面變黑了:
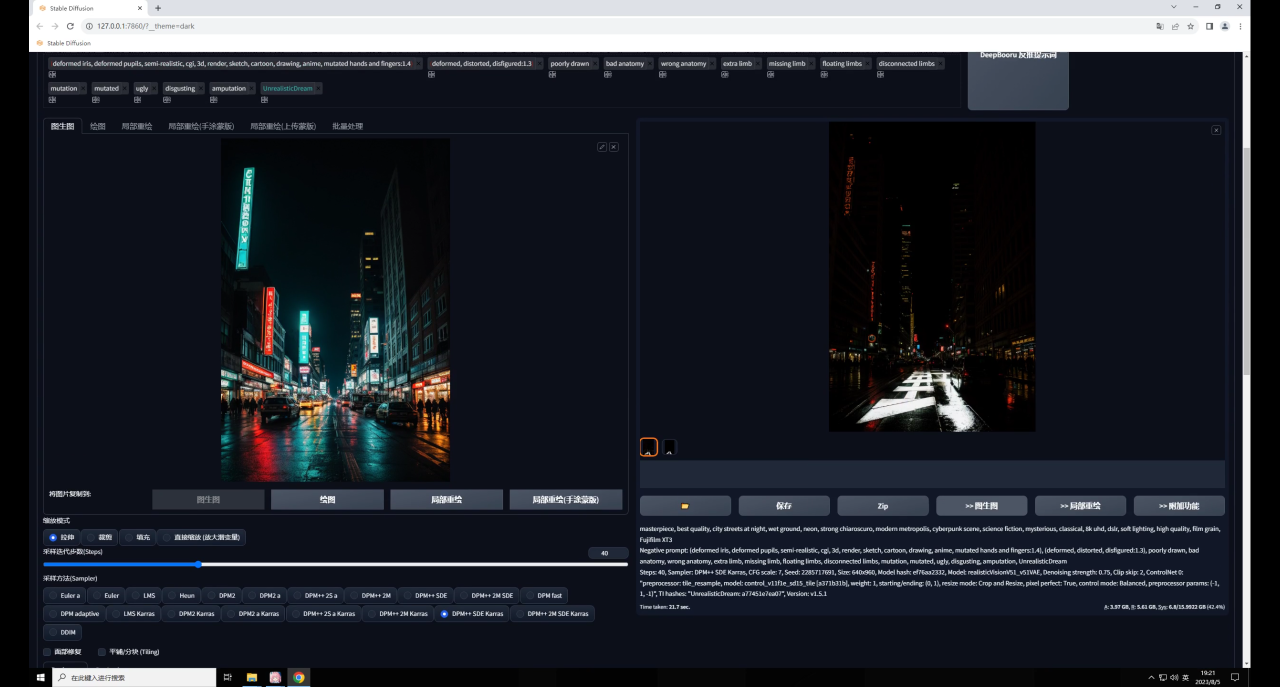
這是因?yàn)門ile的影響太大了,我們可以適當(dāng)?shù)恼{(diào)整權(quán)重以及開(kāi)始和結(jié)束控制的介入步數(shù)。
這三個(gè)參數(shù)的數(shù)值不是固定的,和你的原圖有關(guān),大家實(shí)際操作中可以自行測(cè)試:
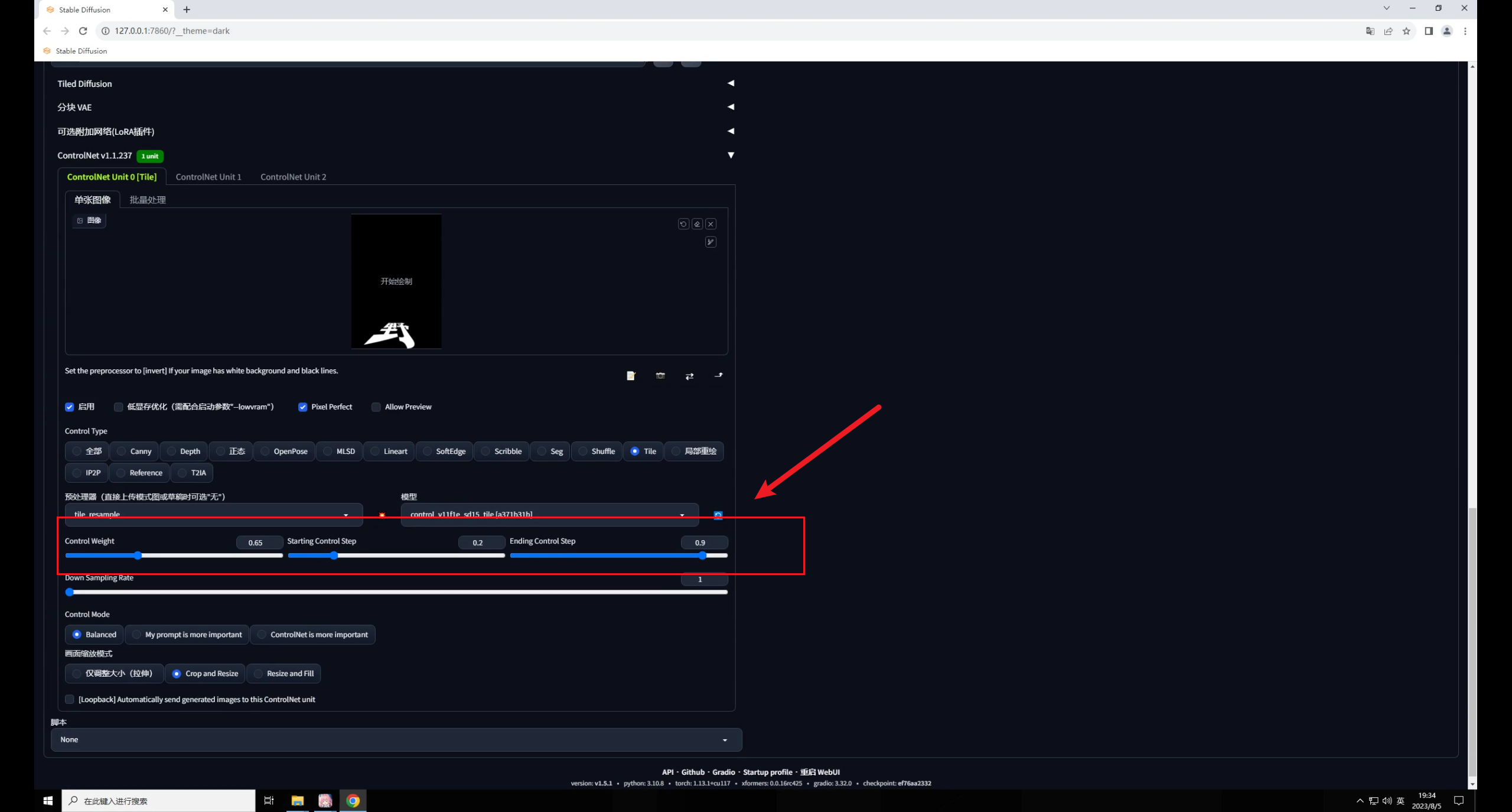
當(dāng)我們適當(dāng)調(diào)整參數(shù)以后,效果就好多了:
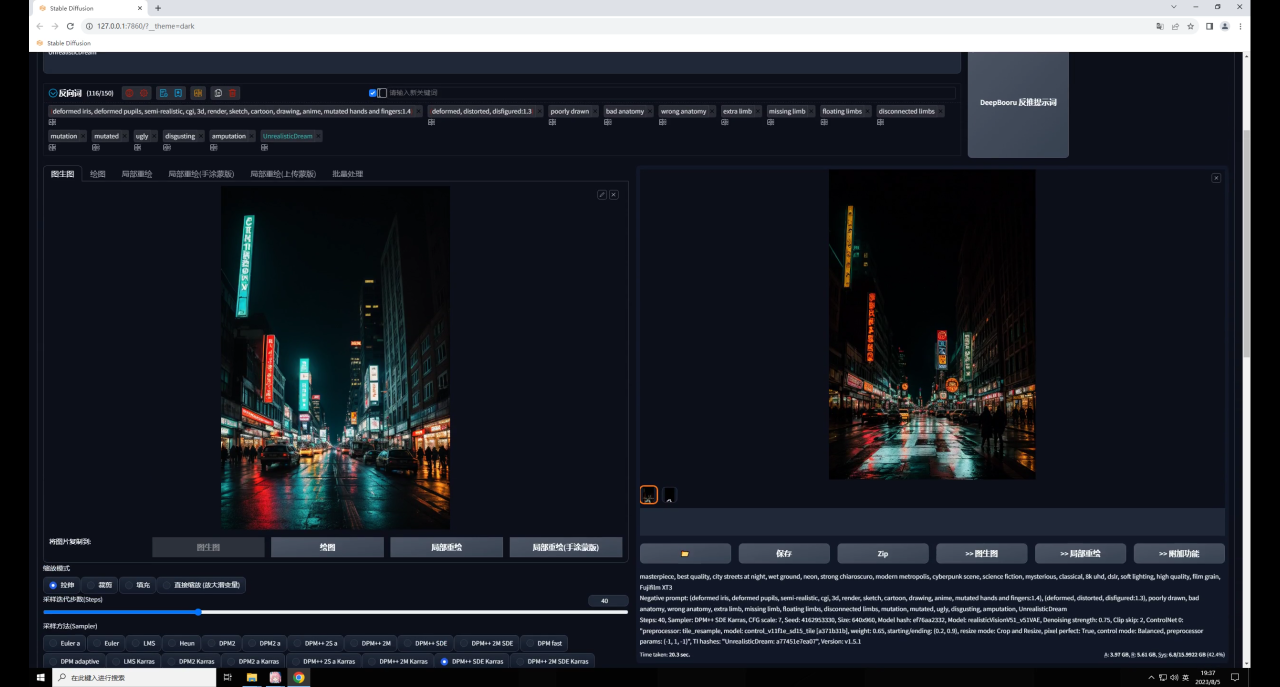
不過(guò)你可能會(huì)發(fā)現(xiàn)生成的圖和原圖差別比較大,這是由于我們圖生圖的重繪幅度過(guò)高導(dǎo)致的:
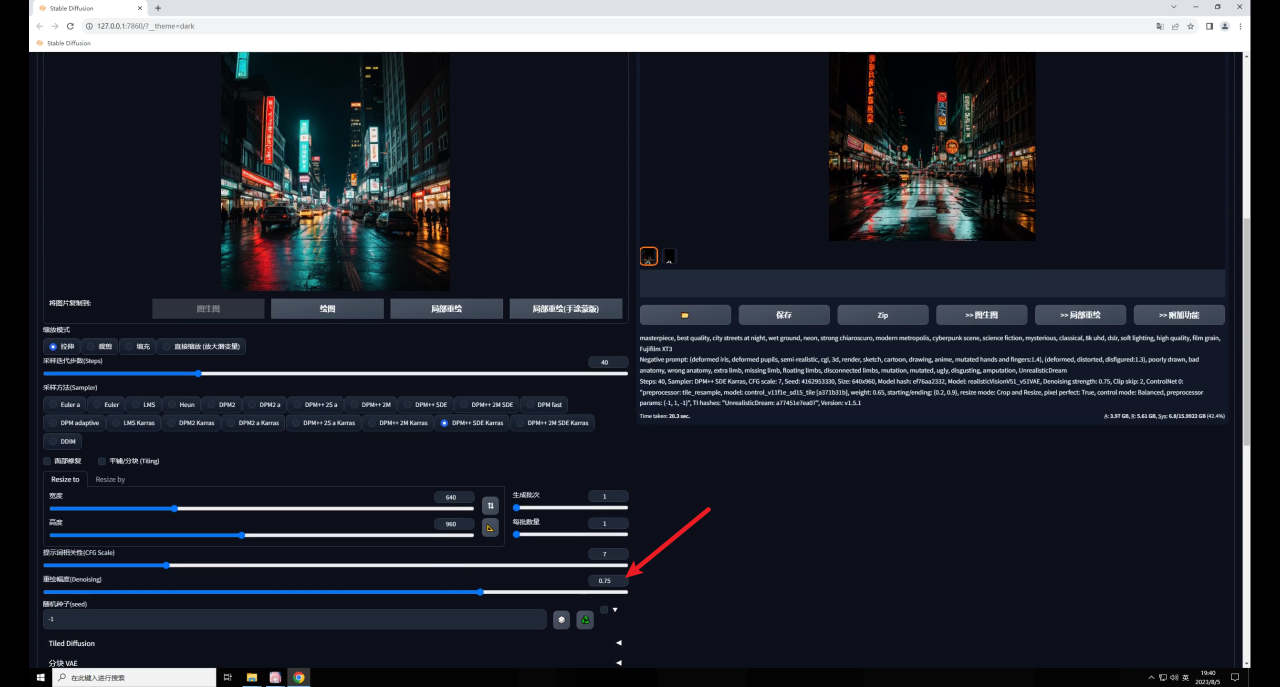
如果你希望生成的圖像盡量和原圖相似,可以適當(dāng)?shù)慕档椭乩L幅度:
但需要注意的是降低重繪幅度也會(huì)降低Tile對(duì)生成圖的影響,我們前面也提到了,Tile會(huì)繪制新的細(xì)節(jié),重繪幅度降低了當(dāng)然影響就弱了。
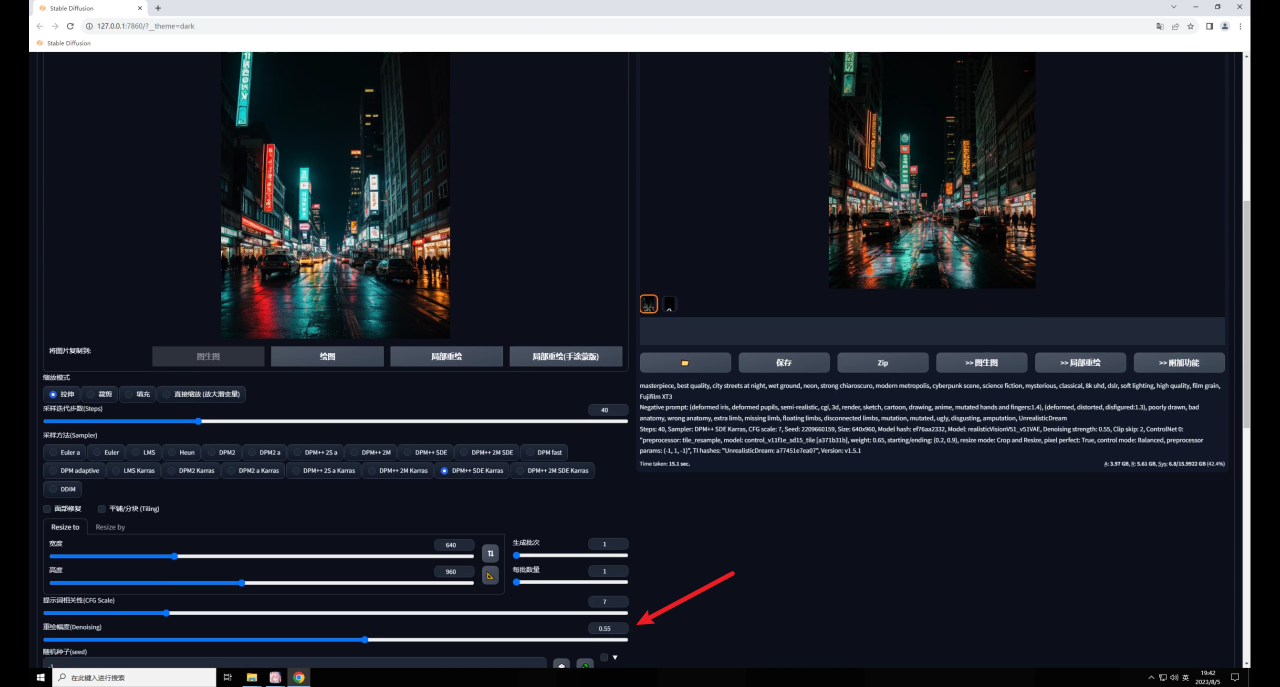
因此如果希望生成圖和原圖保持一致,就需要低重繪幅度高權(quán)重,反之同理,我這里將權(quán)重提高到了0.8,感覺(jué)是我想要的效果:
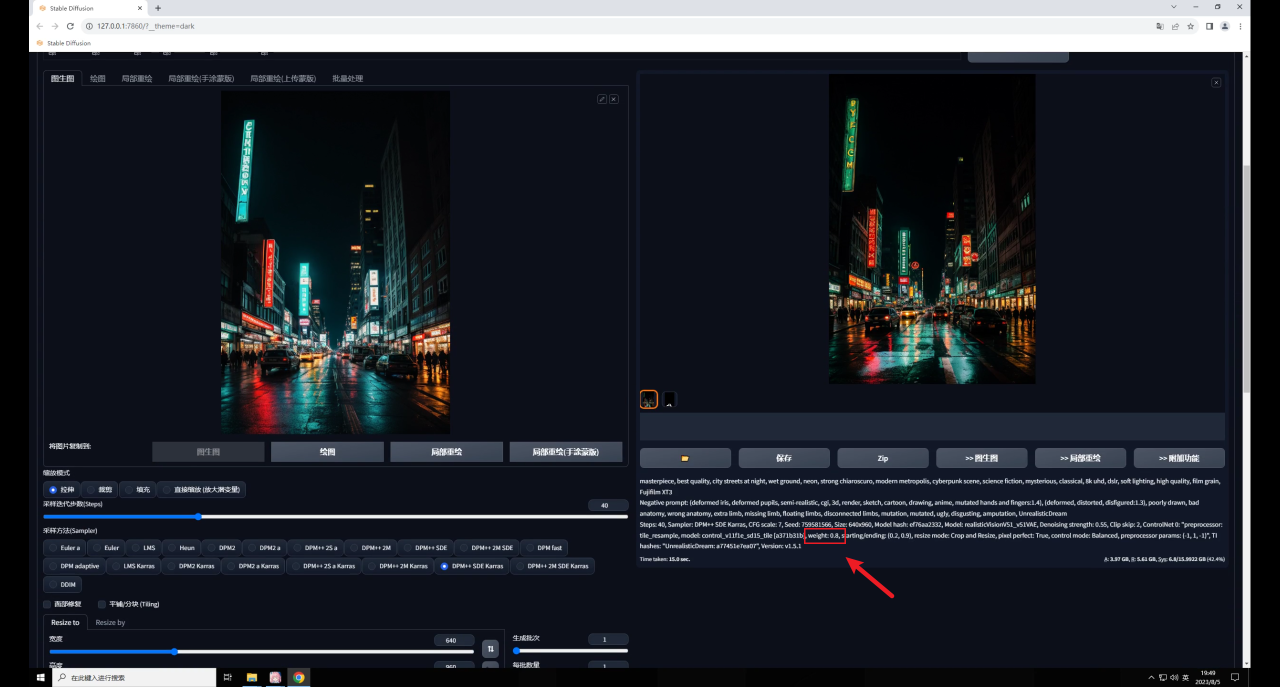
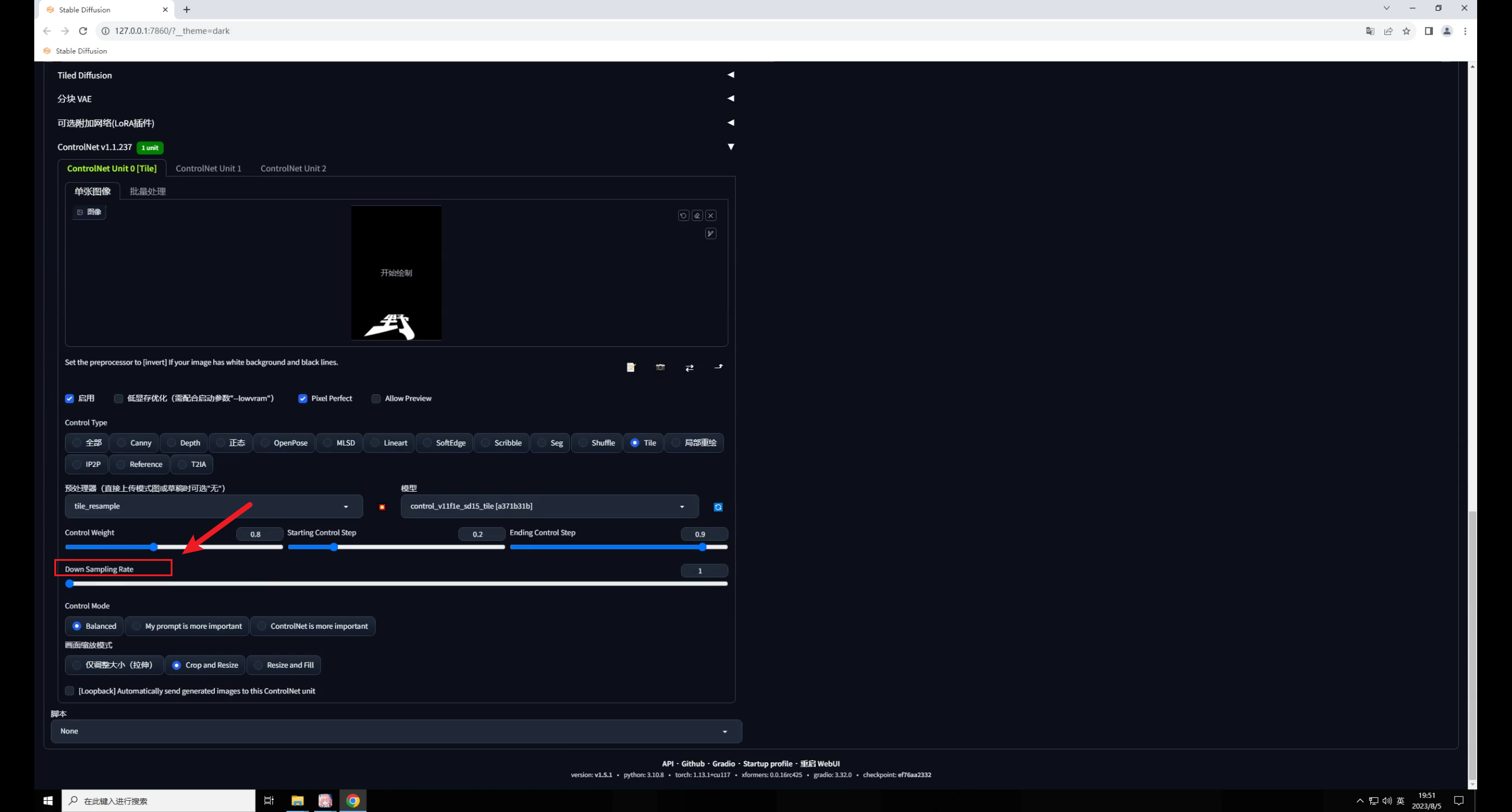
Tile還有一個(gè)降低采樣率的參數(shù),這個(gè)數(shù)值越高,重繪的細(xì)節(jié)越少:
最后放大圖看看效果吧:

03
使用第三方模型制作
第二種方法是使用兩種第三方訓(xùn)練的模型。
第一款在C站上的名字叫 ,在抱臉網(wǎng)上的名字叫:
第二款在C站的名字叫:
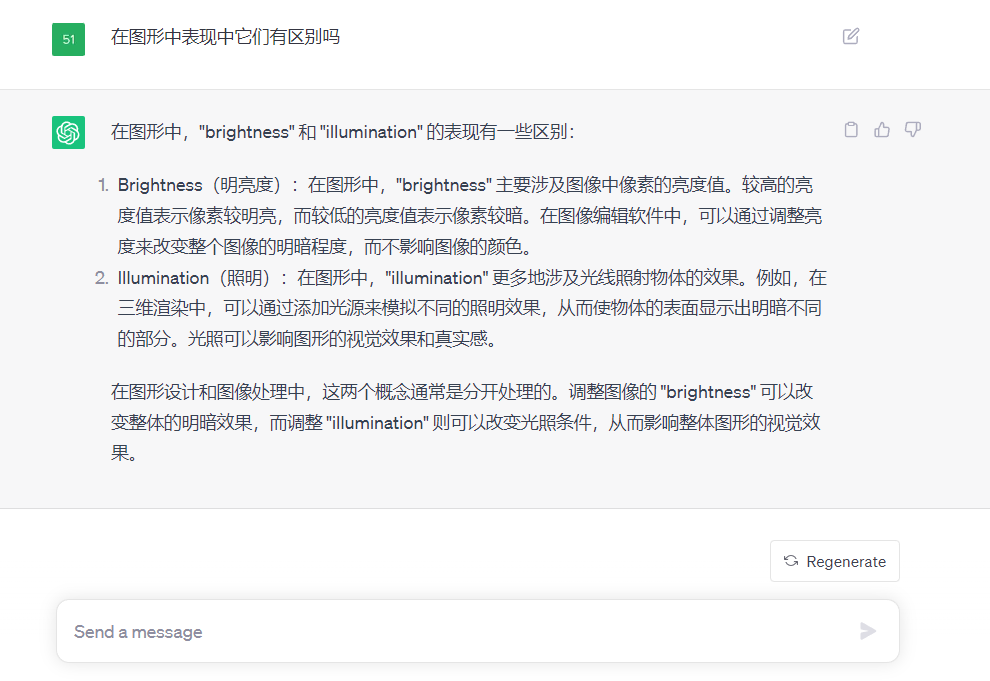
這兩個(gè)名字很相似,是照明,是明亮度,兩個(gè)模型可以單獨(dú)使用。
相比于Tile模型,這兩款模型更偏向于制作光影的效果,下面是對(duì)它們的區(qū)別解釋:
這兩款模型可能是同一個(gè)團(tuán)隊(duì)訓(xùn)練的,文后我也會(huì)把這兩款模型分享給大家:
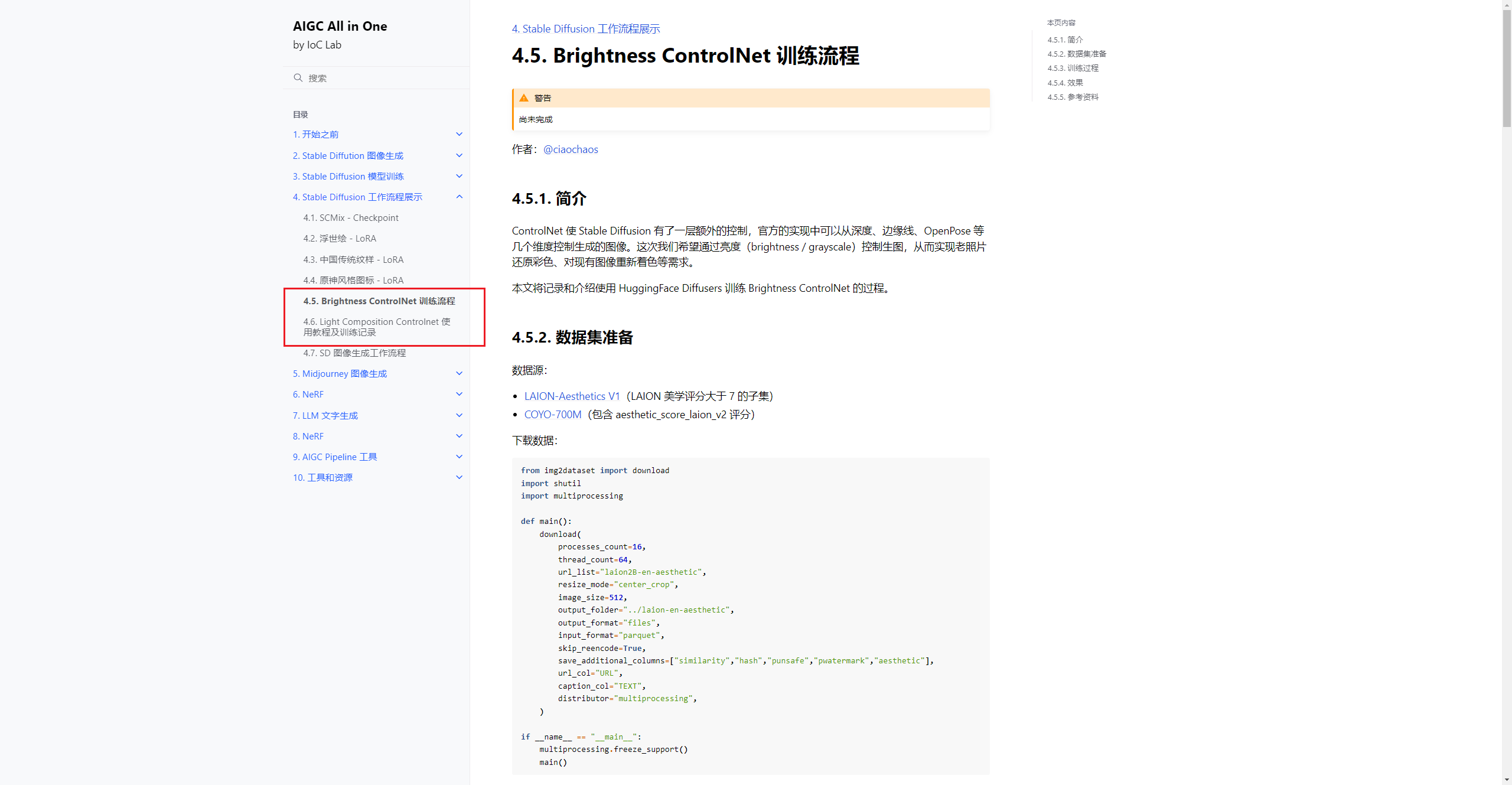
使用的思路方面是Tile模型是一樣的,首先是 這個(gè)模型。
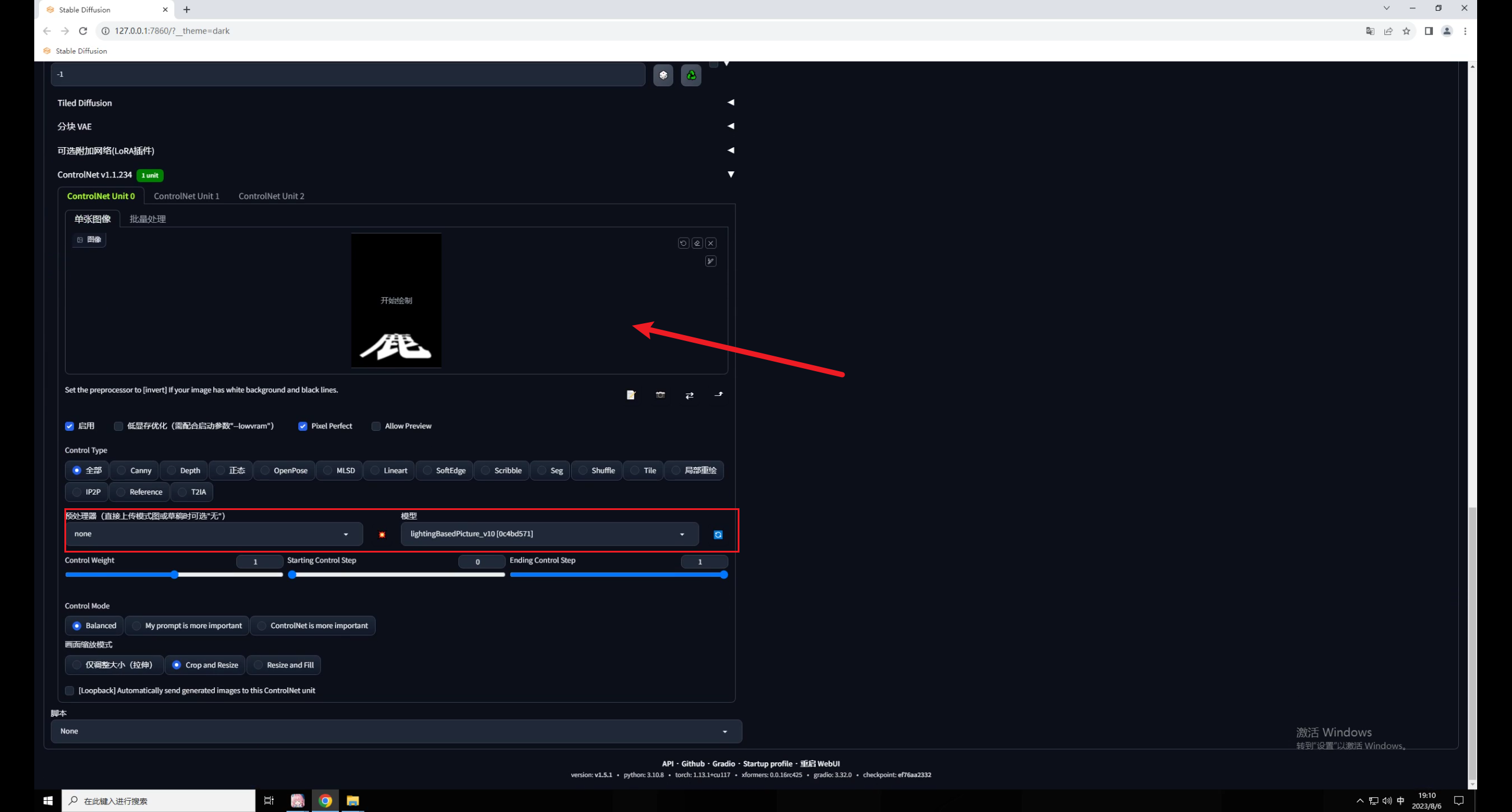
載入文字圖片,預(yù)處理器這里選擇無(wú),模型選擇 :
注意,我現(xiàn)在的重繪幅度是默認(rèn)的0.75,直接點(diǎn)擊生成看一下,同樣畫(huà)面變得很暗,文字過(guò)于清晰:
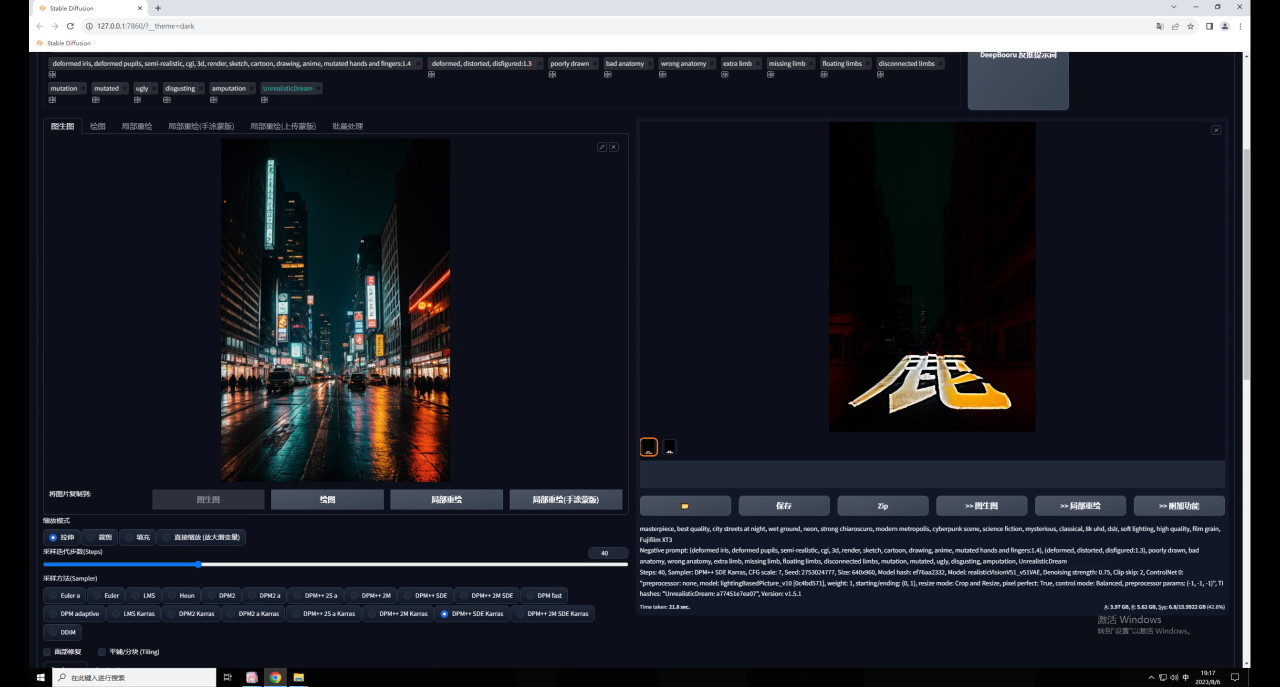
因此同樣調(diào)整參數(shù),權(quán)重0.35,開(kāi)始和結(jié)束控制的介入步數(shù)分別是0.2和0.9,效果就好多了:

同樣的如果你希望畫(huà)面盡量保持不變,就需要降低重繪幅度,然后提高的權(quán)重:
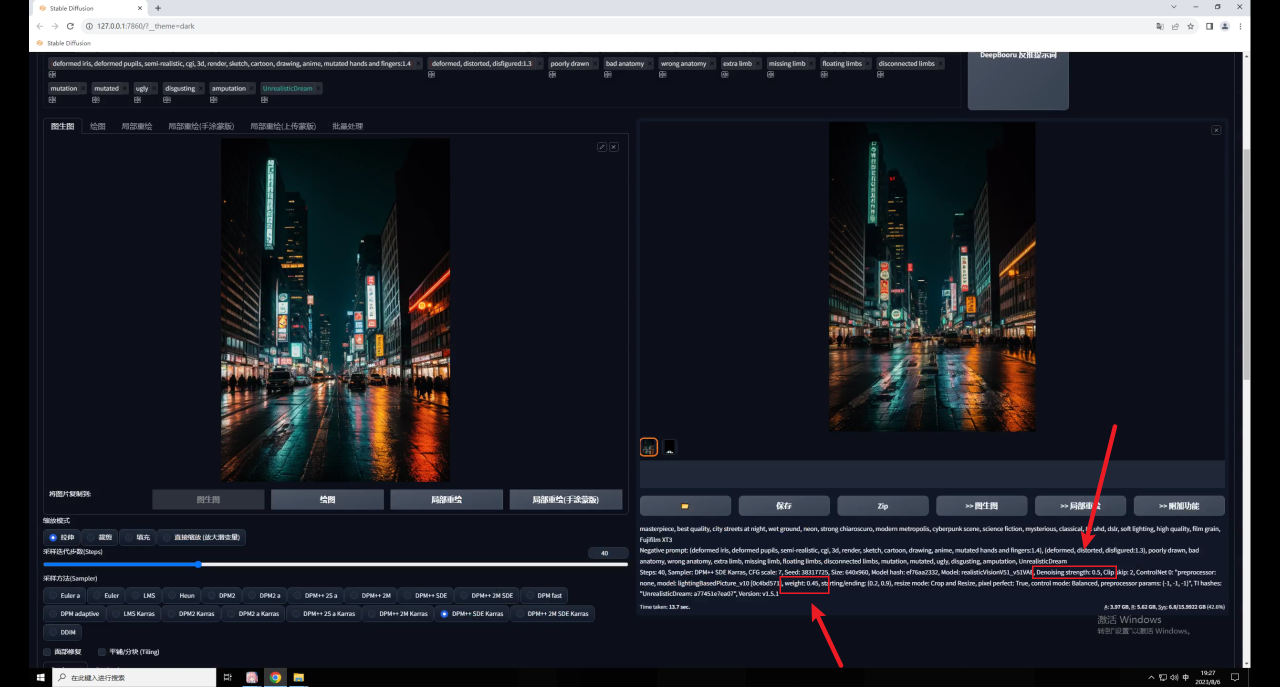
放大圖片看看效果吧:

至于模型也是一樣,無(wú)非就是測(cè)試這三個(gè)關(guān)鍵參數(shù),預(yù)處理器選擇無(wú)就行:
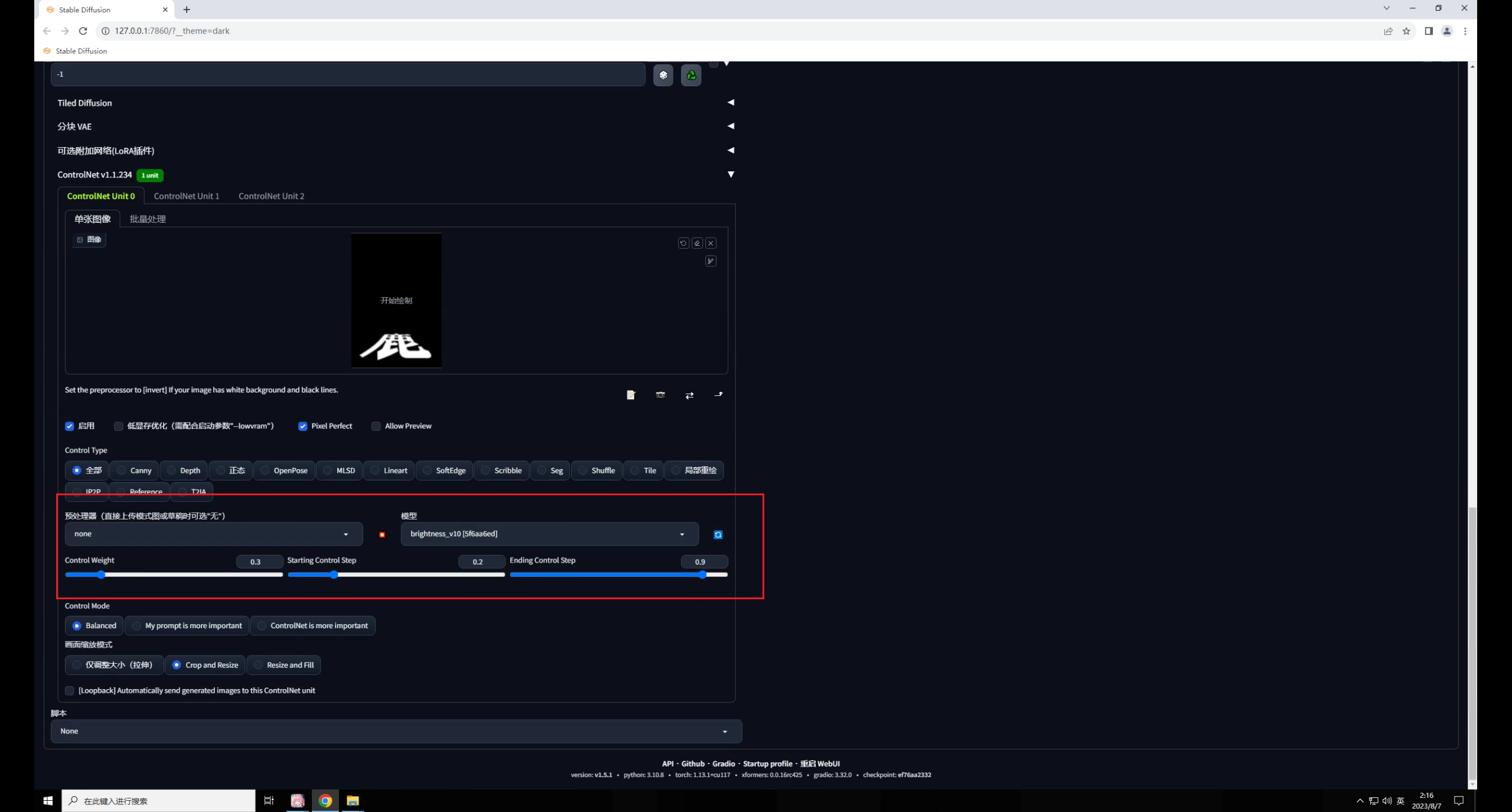
這個(gè)是放大后的效果:

04
使用+輪廓類模型制作
這是我自己研究的方法,只能用于圖生圖,并且可控性不高,隨機(jī)性很大,大家僅做了解吧!
首先通過(guò)圖片信息功能,在提示詞欄位輸入和生成圖相同的題詞:
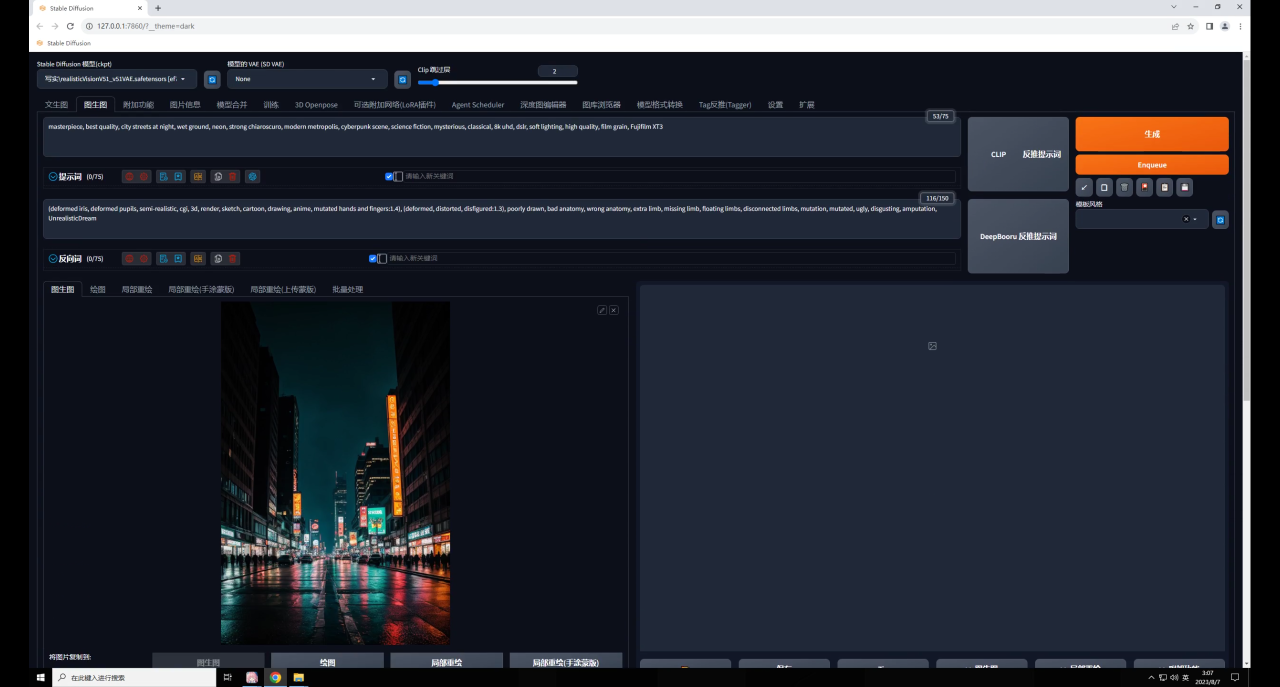
在文生圖輸入欄位把原圖替換為文字圖:
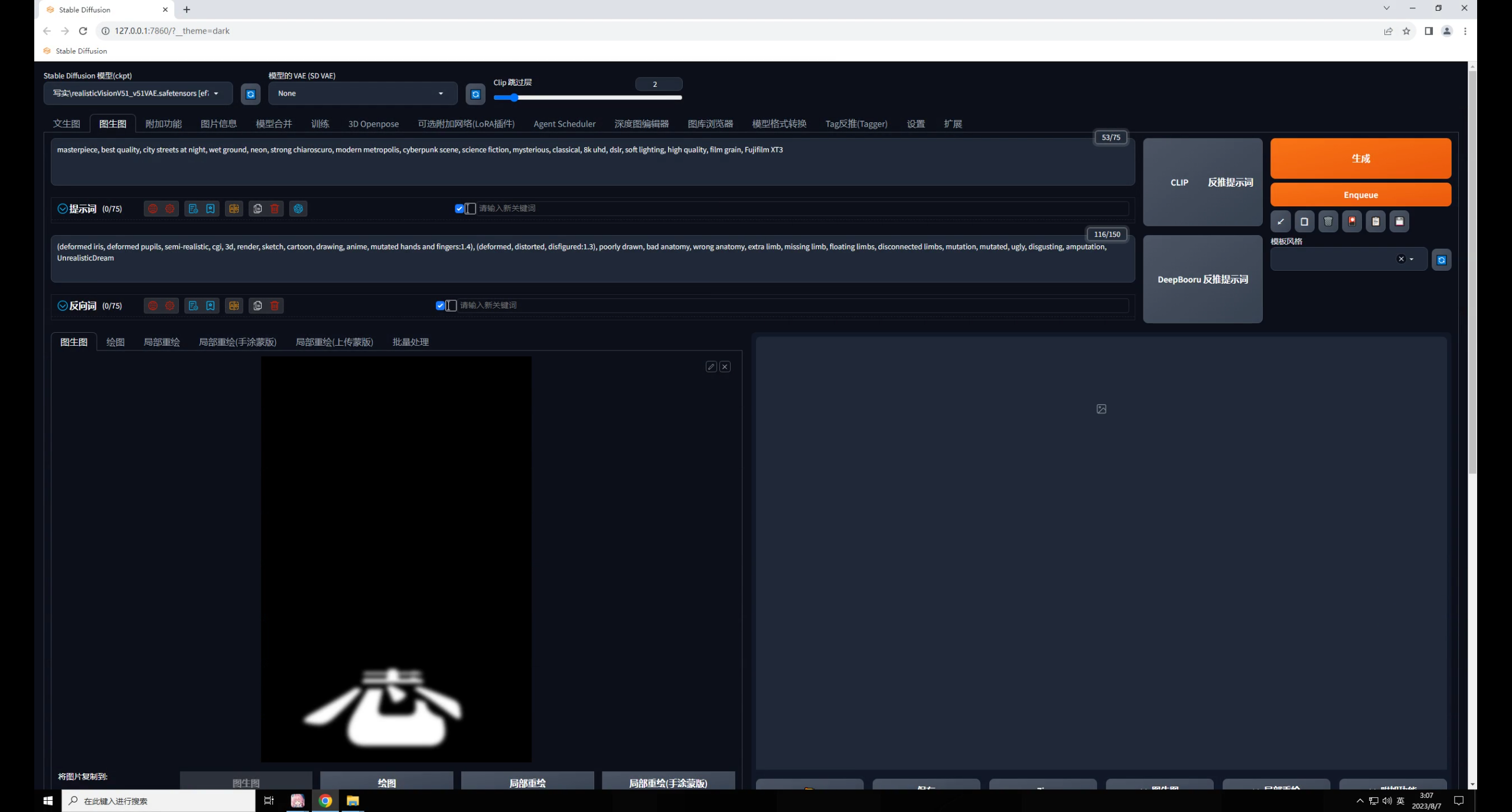
再在中載入夜景圖,模型選擇深度圖,預(yù)處理器用最精準(zhǔn)的 ++,爆炸一下:
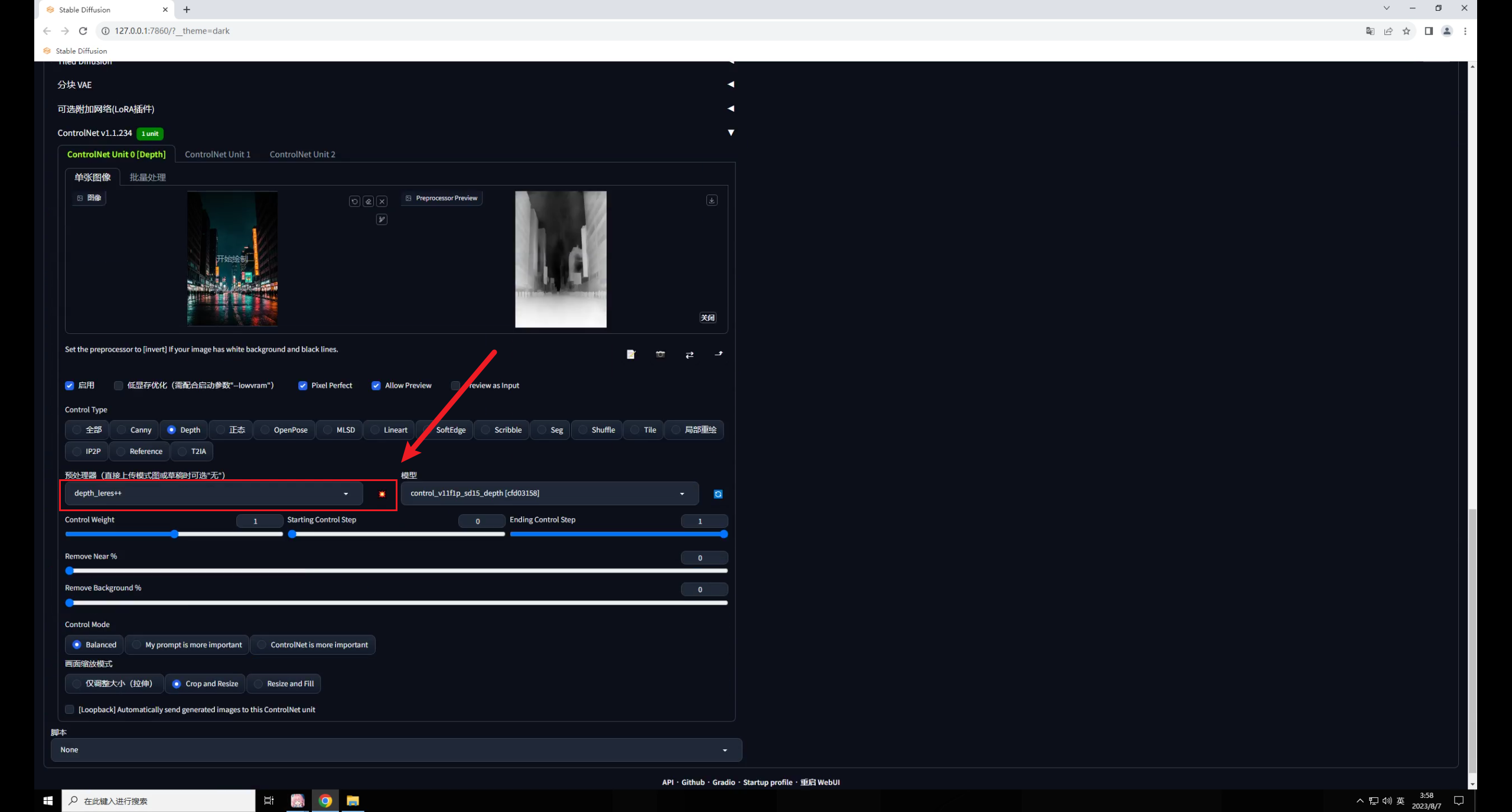
默認(rèn)重繪幅度0.75,點(diǎn)擊生成你會(huì)發(fā)現(xiàn)圖片變暗了,文字識(shí)別也不太準(zhǔn)確。
圖片變暗是由于圖生圖識(shí)別的是輸入圖的顏色信息,圖片大部分是黑色,所以會(huì)變暗。
而文字識(shí)別不太準(zhǔn)確是因?yàn)殡m然圖生圖能讀取顏色信息,但0.75的重繪幅度足以讓生成圖與原圖產(chǎn)生較大的差異,并且設(shè)置中沒(méi)有能固定文字的設(shè)置:

因此我們需要再加入一個(gè)能固定文字形態(tài)的控制,比如在第二個(gè)中加入一個(gè)軟化邊緣的模型,預(yù)處理器我這里選擇的是 hed:
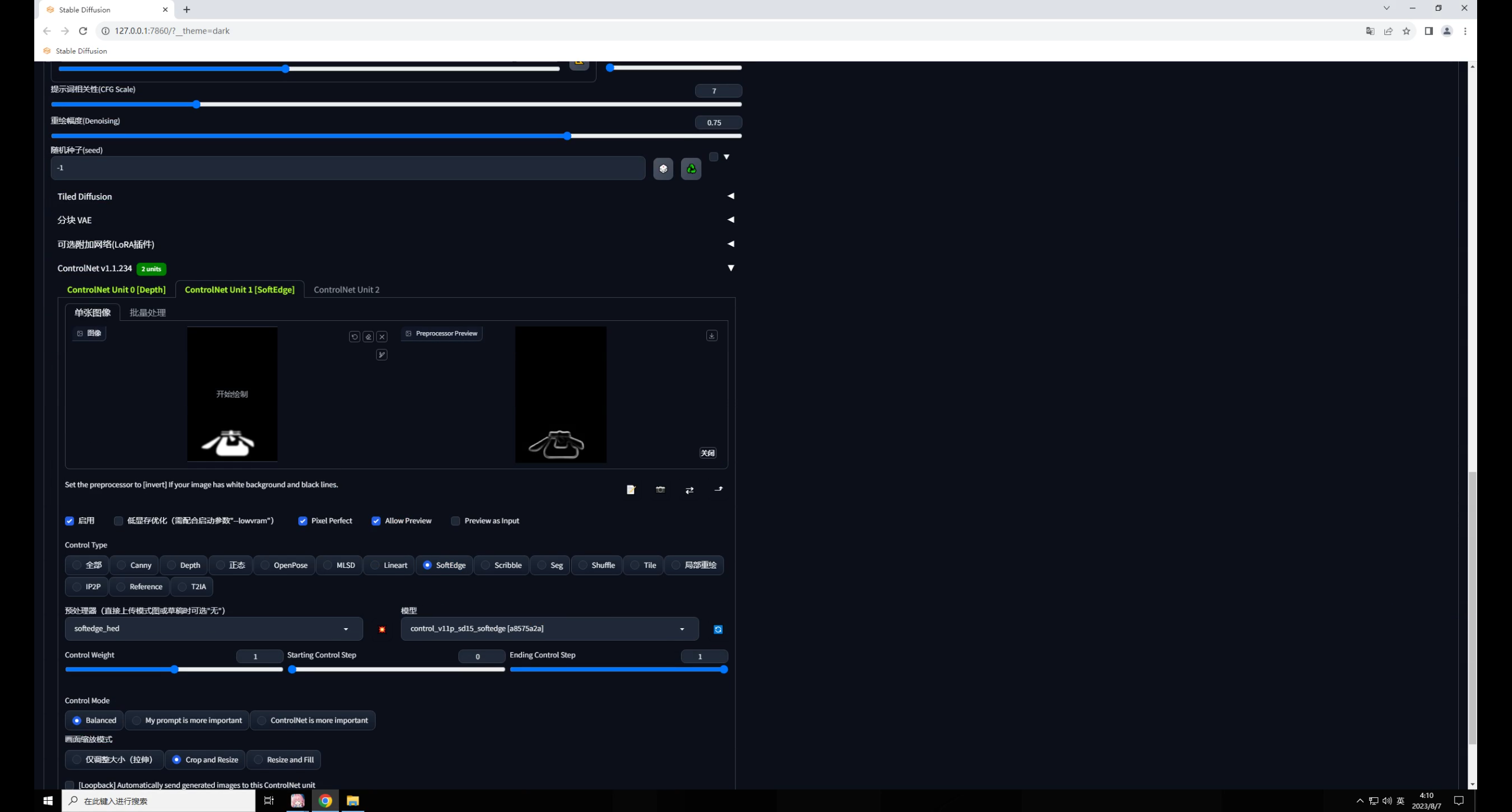
權(quán)重可以適當(dāng)降低一點(diǎn),然后就開(kāi)始抽卡,你會(huì)發(fā)現(xiàn)圖片很暗并且文字過(guò)于清晰。
這是是由于重繪幅度還不夠?qū)е碌模驗(yàn)檫@次我們是直接在圖生圖中輸入的是文字圖:
這種方法的思路是在.1之前,幾乎沒(méi)有模型能夠識(shí)別圖片的顏色信息。
因此我們可以借助圖生圖識(shí)別圖片顏色信息的功能告訴SD什么地方是亮的,同時(shí)用模型控制深度關(guān)系,最后再用輪廓類的模型來(lái)進(jìn)一步限制文字的外形。
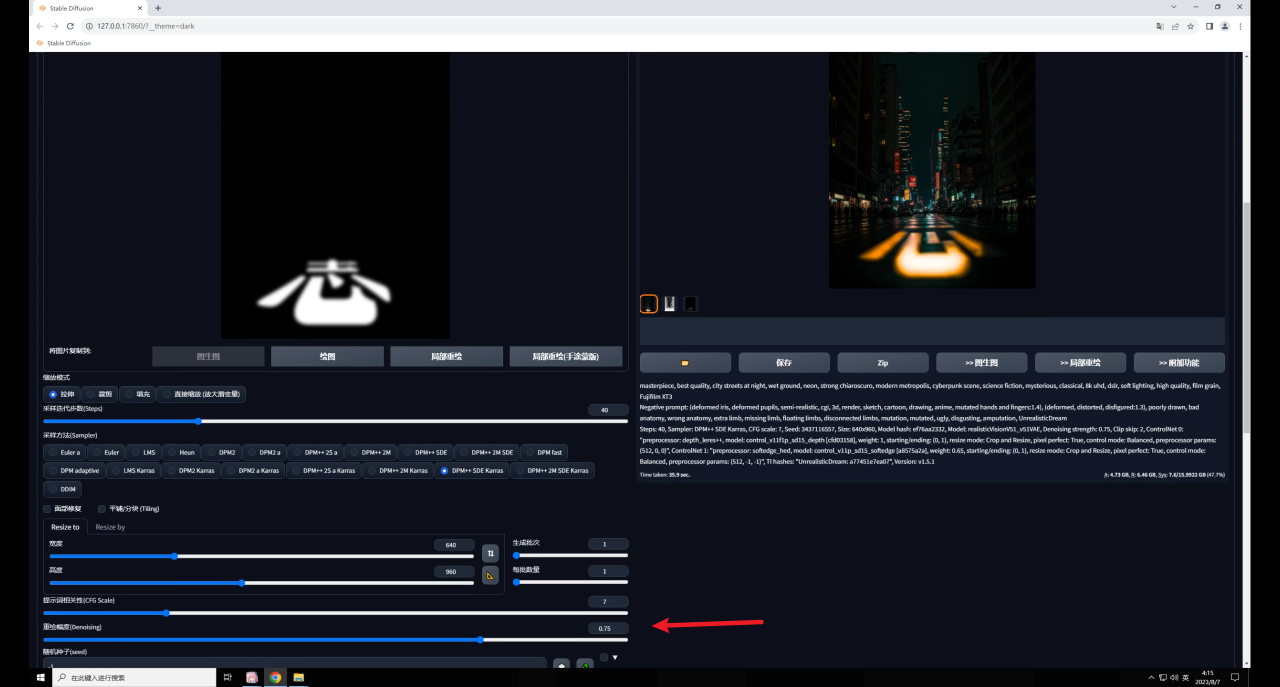
我們可以再次提高重繪幅度,然后抽卡得到一個(gè)感覺(jué)還不錯(cuò)的效果:
不過(guò)這種方法最大的問(wèn)題是可控性比較差,你可能需要多次抽卡才能得到一張比較滿意的圖,并且由于重繪幅度高,所以生成圖與原圖的差異也比較大。
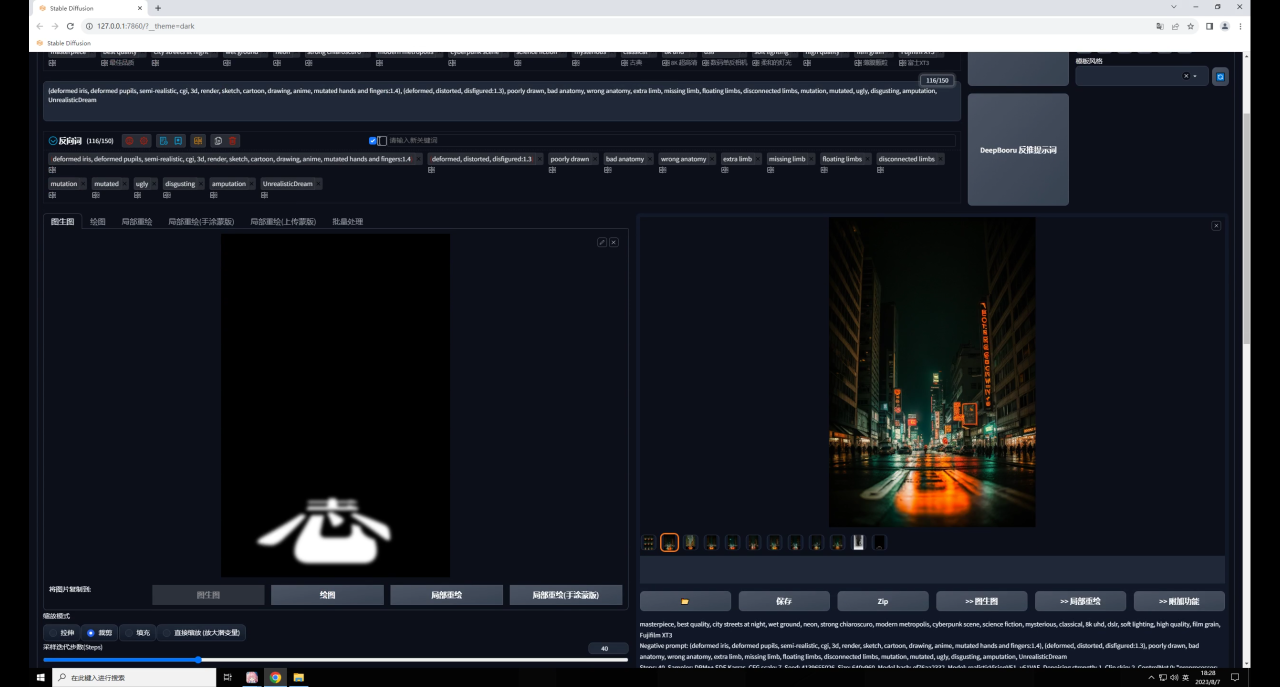
最后圖片放大看看效果吧:

聲明:本站所有文章資源內(nèi)容,如無(wú)特殊說(shuō)明或標(biāo)注,均為采集網(wǎng)絡(luò)資源。如若本站內(nèi)容侵犯了原著者的合法權(quán)益,可聯(lián)系本站刪除。