基于ChatGPT的視頻智能摘要實戰
隨著在 上提交的大量新視頻,很容易感到挑戰并努力跟上我想看的一切。我可以與我每天將視頻添加到“稍后觀看”列表中的經歷聯系起來chatgpt生成視頻文本,只是為了讓列表變得越來越長,實際上并沒有稍后再看。現在,像 或 這樣的大型語言模型為這個長期問題提供了一個潛在的解決方案。
通過將數小時的視頻內容轉換為幾行準確的摘要文本,視頻摘要器可以快速為我們提供視頻的要點,這樣我們就不必花費大量時間來完整觀看它。在我創建這個網絡應用程序之后,我最常使用的場景是參考它的摘要來決定某個視頻是否值得觀看,尤其是那些輔導、脫口秀或演示視頻。
你可以通過多種方式使用強大的語言模型來完成此視頻摘要。
一種選擇是使用或設計 插件,它可以將令人難以置信的 AI 連接到實時 網站。但是,只有少數商業開發人員可以訪問 插件,因此這對包括我在內的所有人來說可能不是最可行的途徑。
另一種選擇是下載視頻的抄本(字幕)并將其附加到提示中,然后要求語言模型通過發送提示來總結抄本文本。然而,這種方法有一個很大的缺點——你不能總結一個包含超過 4096 個標記的視頻,這對于一個普通的談話節目來說通常是 7 分鐘左右。
一個更有前途的選擇是使用上下文學習技術對轉錄本進行向量化,并使用向量向語言模型提示“摘要”查詢。這種方法可以生成準確的答案,指示轉錄文本的摘要,并且不限制視頻長度。
如果你有興趣開發自己的上下文學習應用程序,我之前關于構建聊天機器人以學習和聊天文檔的文章提供了一個很好的起點。通過一些細微的修改,我們可以應用相同的方法來創建我們自己的視頻摘要器。在本文中,我將逐步指導你完成開發過程,以便你了解并復制自己的視頻摘要器。
1、功能框圖
在這個 應用程序中,我們以-為基礎,開發了一個 web應用程序,為用戶提供視頻URL的輸入以及屏幕截圖、文字記錄和摘要內容的顯示。使用 工具包,我們不必擔心 中的 API 調用,因為對嵌入使用的復雜性或提示大小限制的擔憂很容易被其內部數據結構和 LLM 任務管理所覆蓋。
你有沒有想過為什么我在讓 LLM 生成摘要時設計了幾個查詢而不是一個用于轉錄文本處理的查詢?答案在于情境學習過程。當文檔被送入 LLM 時,它會根據其大小分成塊或節點。然后將這些塊轉換為嵌入并存儲為向量。
當提示用戶查詢時,模型將搜索向量存儲以找到最相關的塊并根據這些特定塊生成答案。例如chatgpt生成視頻文本,如果你在大型文檔(如 20 分鐘的視頻轉錄本)上查詢“文章摘要”,模型可能只會生成最后 5 分鐘的摘要,因為最后一塊與上下文最相關 的“總結”。
為了說明這個概念,請看下面的圖表:
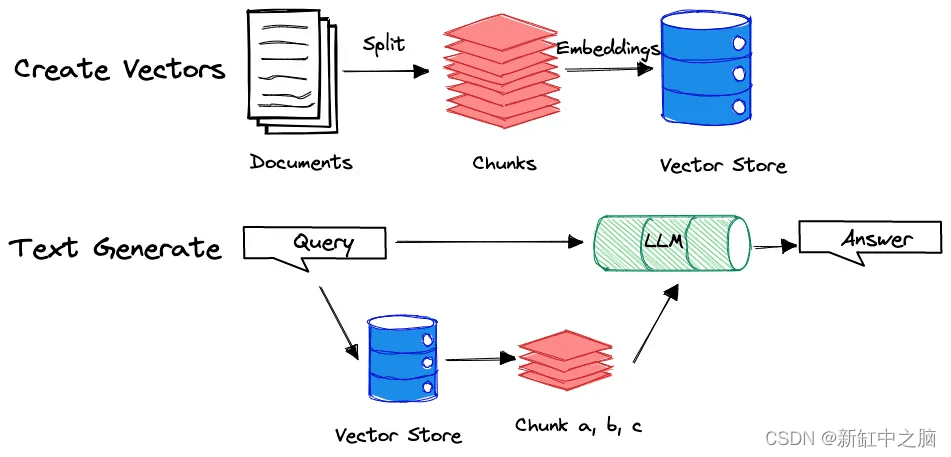
通過設計多個查詢,我們可以促使 LLM 生成更全面的摘要,涵蓋整個文檔。我將在本文后面更深入地組織多個查詢。
從第2章到第5章,我將重點介紹本項目中使用到的所有模塊的基礎知識和典型用法介紹。如果你愿意在沒有這些技術背景的情況下立即開始編寫整個 應用程序,建議你轉到第 6 章。
2、 視頻轉錄文本
總結 視頻的第一步是下載轉錄文本。有一個名為 -tran-api 的開源 庫可以完美滿足我們的要求。
使用如下命令安裝模塊后,
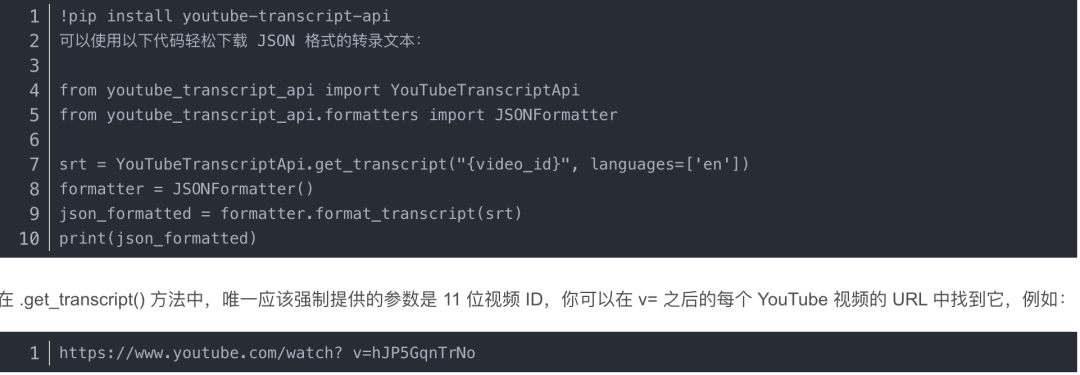
當視頻提供英語以外的其他語言時,可以將它們添加到參數語言中,該參數語言作為包含不同語言的列表。
該庫還提供“”方法來生成具有定義格式的轉錄數據。在這種情況下,我們只需要 JSON 格式即可進行進一步的步驟。
通過運行上面的代碼,你會看到像這樣的一個像樣的轉錄文本:

4、
是一個 庫,充當用戶私有數據和大型語言模型 (LLM) 之間的接口。它有幾個對開發人員有用的功能,包括連接到各種數據源、處理提示限制、創建語言數據索引、將提示插入數據、將文本拆分為更小的塊以及提供查詢索引的接口的能力 . 借助 ,開發人員無需實施數據轉換即可將現有數據用于 LLM,管理 LLM 與數據的交互方式,并提高 LLM 的性能。
可以在此處查看完整的文檔。
以下是使用 的一般步驟:
安裝包:
r 是 工具集中的文件加載器之一。它支持在用戶提供的文件夾下加載多個文件,在本例中,它是子文件夾“./data/”。這個神奇的加載器功能可以支持解析各種文件類型,如.pdf、.jpg、.png、.docx等,讓您不必自己將文件轉換為文本。在我們的應用程序中,我們只加載一個文本文件 (.json) 來包含視頻轉錄數據
— 構建索引
5、Web開發
與我文章中之前的項目一樣,我們將繼續使用方便的 工具集來構建 應用程序。
是一個開源的 庫,有助于創建交互式 Web 應用程序。它的主要目的是供數據科學家和機器學習工程師用來與他人分享他們的工作。借助 ,開發人員可以使用最少的代碼創建應用程序,并且可以使用單個命令輕松地將它們部署到 Web。
它提供了多種可用于創建交互式應用程序的小部件。這些小部件包括按鈕、文本框、滑塊和圖表。可以從其官方文檔中找到所有小部件的用法。
Web 應用程序的典型 代碼可以像下面這樣簡單:

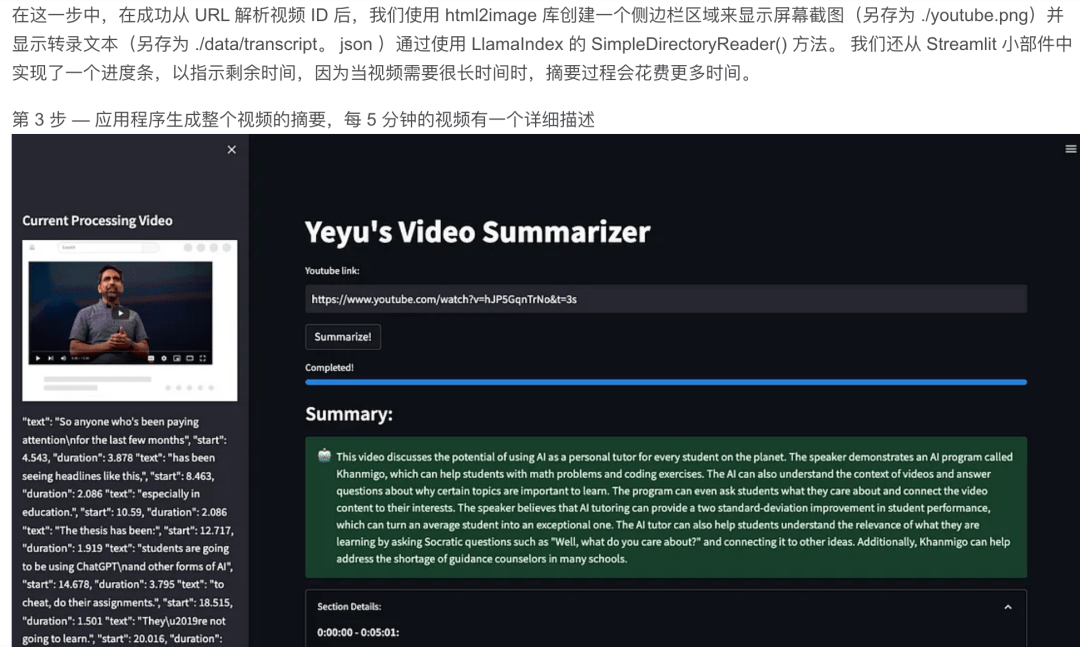

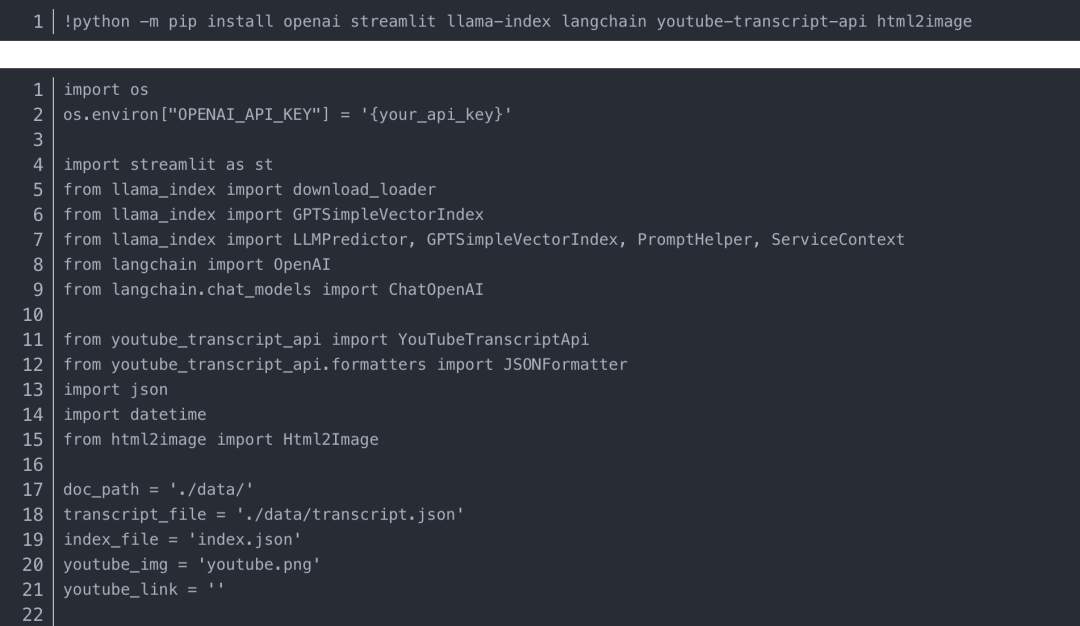
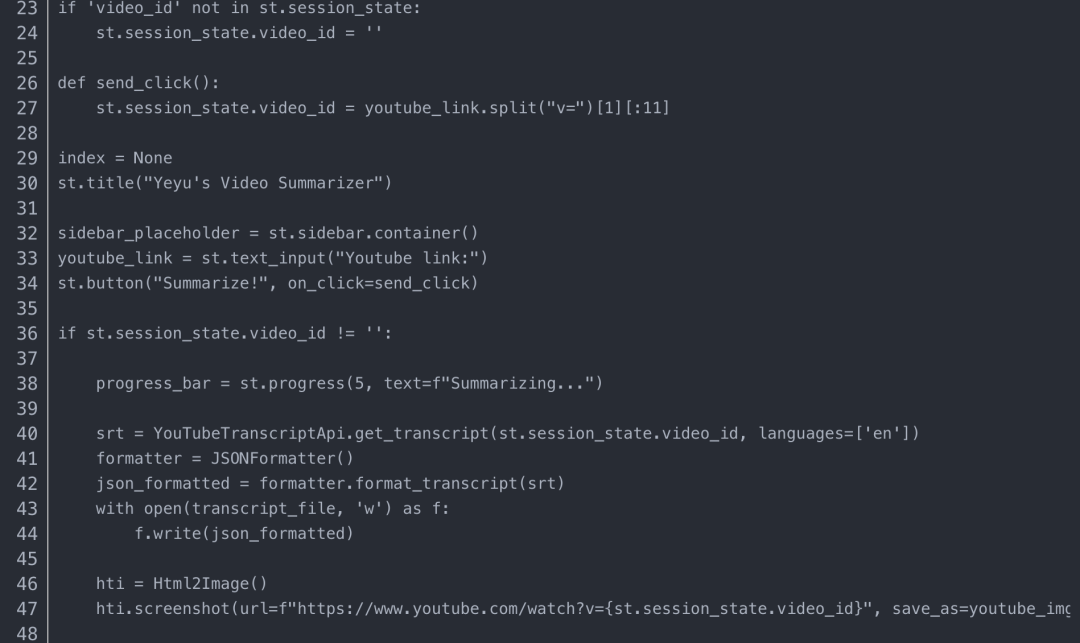

將代碼保存到 文件“demo.py”,創建一個 ./data/ 文件夾,然后運行命令:
! -m run demo.py
現已準備就緒,能夠簡單而有效地執行其任務。
注意——請從一段短視頻開始測試,因為長視頻會花費你大量的 API 使用費。在繼續之前,還請檢查視頻是否啟用文本轉錄。
機器學習算法AI大數據技術
搜索公眾號添加:
閱讀過本文的人還看了以下文章:
2.0深度學習案例實戰
基于40萬表格數據集,用做表格檢測
《基于深度學習的自然語言處理》中/英PDF
Deep 中文版初版-周志華團隊
【全套視頻課】最全的目標檢測算法系列講解,通俗易懂!
《美團機器學習實踐》_美團算法團隊.pdf
《深度學習入門:基于的理論與實現》高清中文PDF+源碼
《深度學習:基于的實踐》PDF和代碼
特征提取與圖像處理(第二版).pdf
就業班學習視頻,從入門到實戰項目
2019最新《自然語言處理》英、中文版PDF+源碼
《21個項目玩轉深度學習:基于的實踐詳解》完整版PDF+附書代碼
《深度學習之》pdf+附書源碼
深度學習快速實戰入門《-》
【下載】豆瓣評分8.1,《機器學習實戰:基于-和》
《數據分析與挖掘實戰》PDF+完整源碼
汽車行業完整知識圖譜項目實戰視頻(全23課)
李沐大神開源《動手學深度學習》,加州伯克利深度學習(2019春)教材
筆記、代碼清晰易懂!李航《統計學習方法》最新資源全套!
《神經網絡與深度學習》最新2018版中英PDF+源碼
將機器學習模型部署為REST API
檢測出圖像中的不規則漢字
同樣是機器學習算法工程師chatgpt生成視頻文本,你的面試為什么過不了?
前海征信大數據算法:風險概率預測
【】完整實現‘交通標志’分類、‘票據’分類兩個項目,讓你掌握深度學習圖像分類
特征工程(一)
特征工程(二) :文本數據的展開、過濾和分塊
特征工程(三):特征縮放,從詞袋到 TF-IDF
特征工程(四): 類別特征
特征工程(五): PCA 降維
特征工程(六): 非線性特征提取和模型堆疊
特征工程(七):圖像特征提取和深度學習
如何利用全新的決策樹集成級聯結構做特征工程并打分?
中文翻譯稿
螞蟻金服2018秋招-算法工程師(共四面)通過
全球AI挑戰-場景分類的比賽源碼(多模型融合)
斯坦福官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院全球文本匹配競賽華人第1名團隊-深度學習與特征工程
不斷更新資源
深度學習、機器學習、數據分析、
搜索公眾號添加:
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。