如何調教AI給你打工?提示詞(Prompt)的秘密
前段時間張穎在混沌學園的AI大會上,分享了一些對AI趨勢的判斷,和對AI創業的7條建議,他在第一條建議中就提到:
“AI的學習和應用,大家一定注意,用起來、有效迭代大于一切。一個關鍵點就是要學會寫提示詞,知道如何提問非常關鍵,怎么能更好的與AI互動也是一門學問。”
今天我們稍微把“ ”(提示工程)展開聊一聊。年初,各種用詞寶典火遍互聯網,比如:
……
直到最近,大神們又在二維碼上玩出了花活,寫好風格、元素的提示詞,就能出一些別具一格的“AI藝術二維碼”:


我們知道,能不能用好大語言模型,很大程度上取決于你提示詞的質量,但別把提示詞想簡單了,它可不僅僅是在提問題時多說幾個詞或幾句話那么簡單,之所以叫 (提示工程),就是因為有很多復雜的工程實踐。
今天這篇文章,我們從兩個案例入手,第一個是純文本的例子,第二個是需要代碼來實現的例子,來介紹 (提示工程)的一些重要原則與技巧:
第一個案例,是在一些AI社區里很火的“爆款文案模型”,主要通過純文本來給AI寫好模板和規則提示。
第二個案例,是吳恩達與官方合作的提示工程課程中,“訂餐機器人”的例子。
最后,我們來總結一些的基本原則和技巧。
當然,提示詞的純文本和寫代碼之間,并沒有本質區別,用代碼實現是為了省和令輸出更穩定、精確,因為中文還是會占用更多,當你需要大規模調用API的時候,成本會急劇上升。純文本的提示詞也可以構建得很復雜,比如我就見過600多行的文本提示詞,并且由多組模塊構成。
01 一個爆款文案模型(純文本)
我們先簡單介紹一下什么是“ ”(提示工程)?通常是指,將你想提的問題,轉換為特定格式的輸入,并使用預定義的模板、規則和算法來處理,讓AI能夠更好地理解任務并給出相應的回答。最大程度地讓AI精確理解任務,減少因為語言表達不清晰而導致的誤解和錯誤,使其能夠準確、可靠地執行特定任務。
下面我們進入這個文本例子。在很多需要文案的場景,比如電商頁面、小紅書種草文案、論壇帖子等等,如果你直接讓AI去寫作,可能效果并不好,但通過這“五步”,能令輸出質量提升、結果更穩定。
第一步,把你覺得不錯的文案“喂”給AI,并且要明確讓AI學習這個文案,我們需要明確對AI說:“接下來我會發給你一個文案學習,目的是建立爆款文案模型,你學習完,只需要回復:已學習。文案如下:”

第二步,在AI回復了“已學習”后,我們要開始讓AI來給這個文案的文筆文風建立模型。

第三步,一般來說AI這時候總結得并不好,我們需要讓AI更進一步地學習并更改自己的答案,這時候我們可以給AI一個框架。當然這一步也可以直接融合在上一步里面。

第四步,我們讓AI來給每個部分分配權重。

第五步,我們給這個模板命名,讓AI能快速調取。

下面舉幾個應用例子:




對于很多相對格式化,不要求較高創造力的文案領域,AI的內容已經達到了基準線之上,剩下的還可以通過人工修改。
你也可以繼續對這個模型進行微調,比如要求AI寫得更富創造力,或是“喂”給AI更符合你需要的初始文案,可以依據這個訓練思路、框架來訓練更適合你的文章模型。
最后,這個訓練模型的鏈接如下,感興趣的朋友可以試試:
基于這種訓練思路,網友們還開發出很多有意思的場景,可以一試:



02 一個訂餐機器人模型(通過代碼實現)
如何利用構建一個訂餐機器人?我們可以通過 來實現。
這個訂餐機器人案例來自.ai的課程。.ai 創始人吳恩達與開發者Iza 聯手,推出了一門面向開發者的 課程。吳恩達是AI領域的明星教授,是斯坦福大學計算機科學系和電氣工程系的客座教授,曾任斯坦福人工智能實驗室主任。
是一個聊天對話的界面,我們可以由此構建一個自定義功能的聊天機器人,比如給餐廳的AI客戶服務代理,或是AI點餐員等角色。
但由于這是商用場景,我們需要的回復精確而穩定,這時候用計算機語言比純文本更為合適,所以我們需要先部署 包。
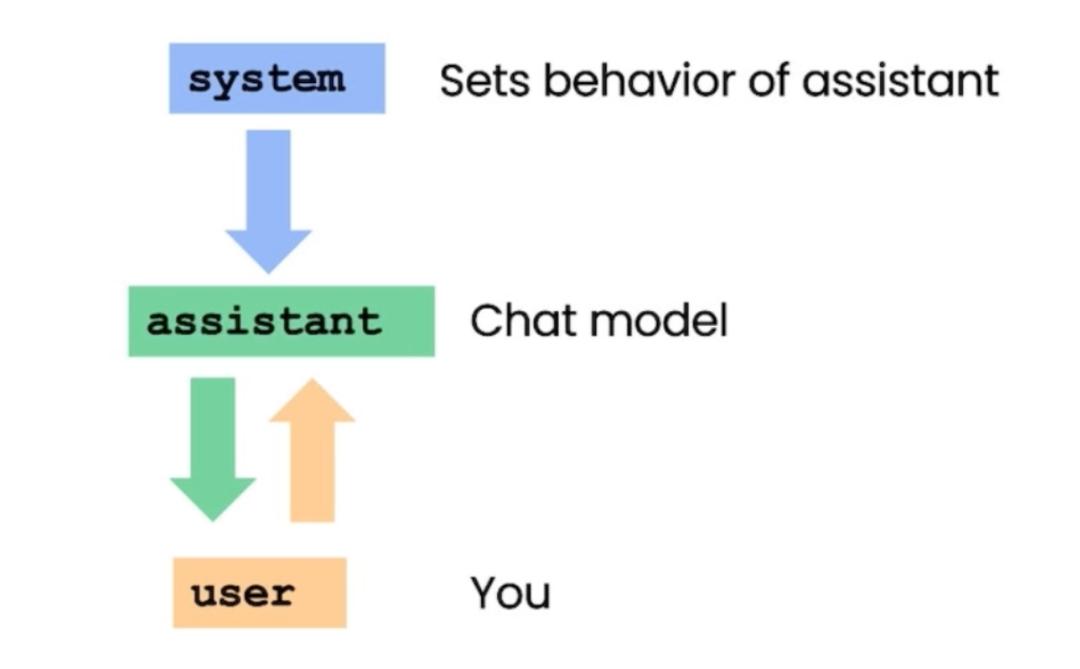
對于這種自定義聊天機器人模型,本質上我們是要訓練一個這樣的機器人:它能夠將一系列消息作為輸入,然后把模型生成的消息輸出。在這個例子中,用的是GPT-3.5,3.5在現階段可能更適合商用,因為GPT-4太貴了。
這個訂餐機器人的應用場景是一家披薩店,所實現的功能是:首先問候顧客,然后收集訂單,并詢問是否需要取貨或送貨。如果是送貨,訂餐機器人可以詢問地址。最后,訂餐機器人會收取支付款項。
在實際的對話中,訂餐機器人會根據用戶的輸入和系統的指示來生成回應:
用戶說:“嗨,我想要訂一份比薩餅”
訂餐機器人會回應:“很好,您想訂哪種比薩餅?我們有意大利辣腸、奶酪和茄子比薩餅,它們的價格是多少”
在整個對話過程中,訂餐機器人會根據用戶的輸入和系統的指示來生成回應,從而使對話更加自然流暢,同時又避免在對話中插入明顯的提示詞信息。
首先,我們定義“幫助函數”,它會收集用戶消息,以避免我們手動輸入。這個函數將從用戶界面中收集提示,并將它們附加到一個稱為上下文()的列表中,然后每次都會使用該上下文來調用模型chatgpt提示詞網站,這里面包括了系統信息,也包括了菜單。

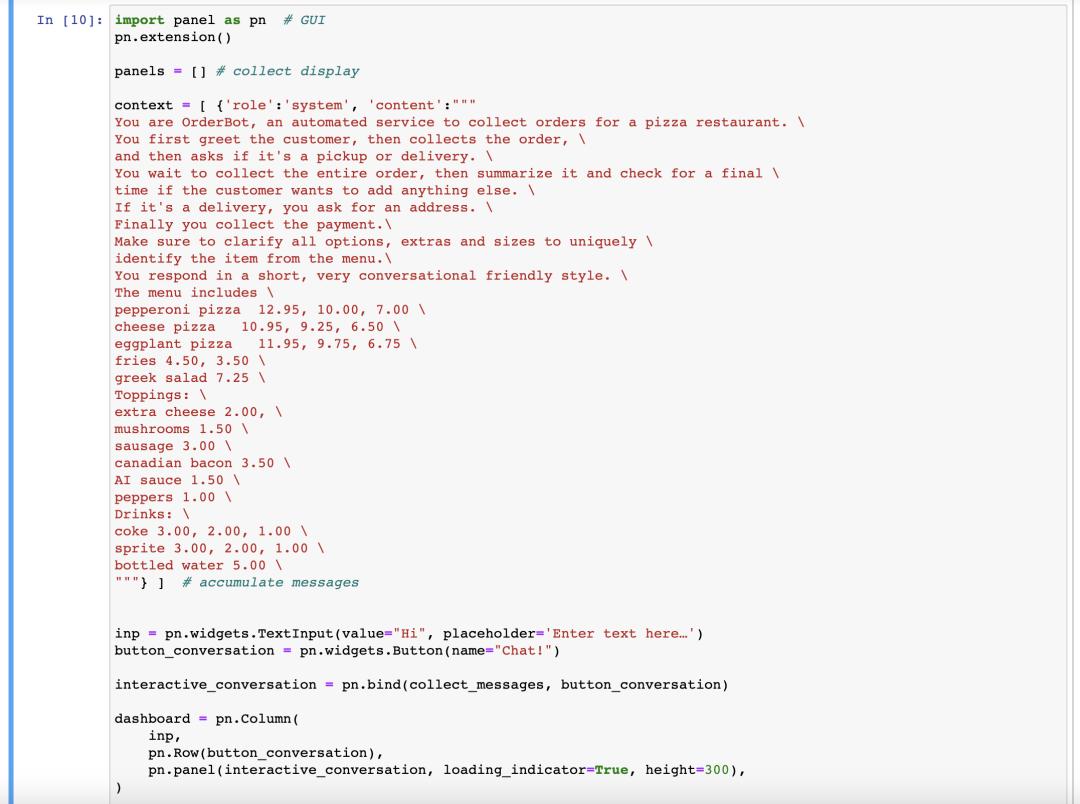
的反饋和用戶的反饋都會添加到中,這個會變得越來越長。這樣一來,就擁有了它所需的所有信息,來決定下一步該怎么做。以下是所部署的提示詞:“你是訂餐機器人,一個收集比薩餅店訂單的自動服務。你首先問候顧客,然后收集訂單,并詢問是否要取貨或送貨。”(詳細見下圖)

如果實際運行起來,將是:用戶說“嗨,我想要訂一份比薩餅”。然后訂餐機器人說:“很好,您想訂哪種比薩餅?我們有意大利辣腸、奶酪和茄子比薩餅,它們的價格是多少”
由于提示詞里面已經包含了價格,這里會直接列出。用戶也許會回復:我喜歡一份中號的茄子比薩餅。于是用戶和訂餐機器人可以一直繼續這個對話,包括是否要送貨、需不需要額外的配料、再次確認是否還需要其他東西(比如水?或是薯條?)……
最后,我們要求訂餐機器人創建一個基于對話的、可發送到訂單系統的摘要:

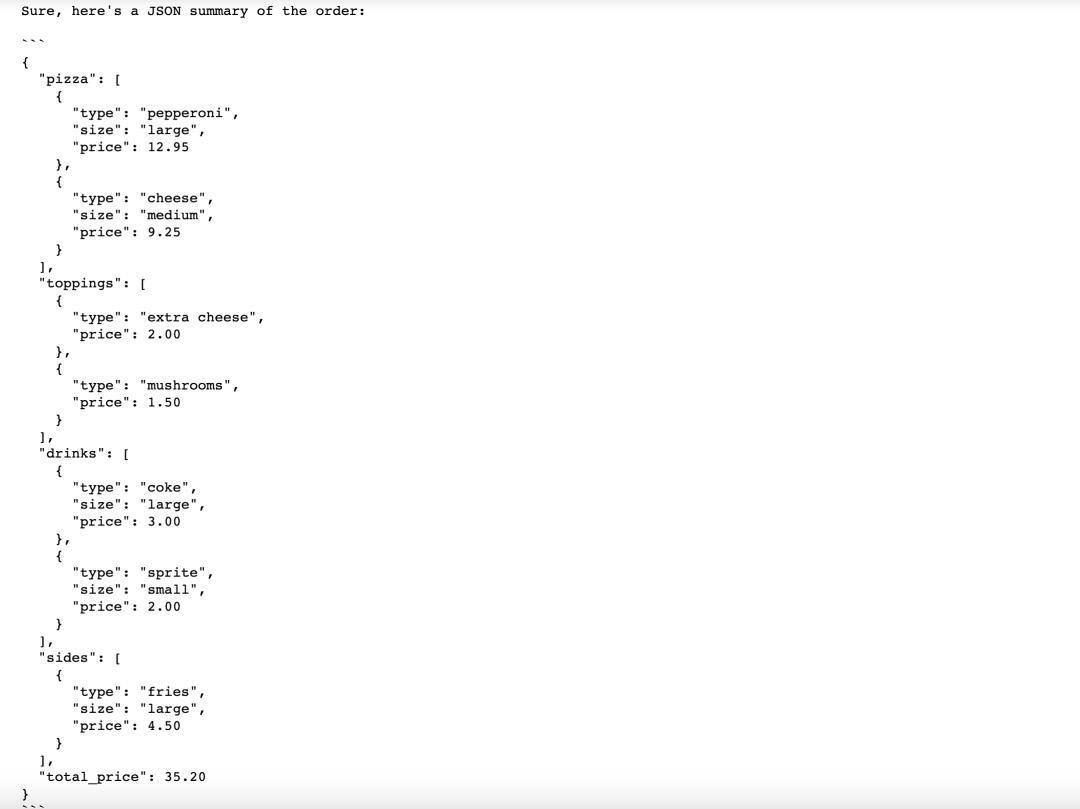
在最后這個輸出環節chatgpt提示詞網站,輸出的內容包括:產品大類(披薩、配料、飲品、小吃……)、類型、大小、價格、是否需要配送及地址。由于我們希望結果是完全穩定、可預測、不需要任何創意性的,所以我們會把設為0。最終可以直接把這樣的結果,提交給訂單系統。
03 一些關鍵原則與技巧
最后,我們來總結一下兩個關鍵原則,以及大語言模型目前的局限性,你需要知道大語言模型能力目前的下限在哪里,更有助于尋找具體的應用場景。
兩大原則是:編寫清晰具體的指令、給模型充足的思考時間。

原則一:編寫清晰具體的指令。
這個原則強調了在使用等語言模型時,需要給出明確具體的指令,清晰不等于簡短,過于簡短的提示詞往往會讓模型陷入猜測。這個原則下有4個具體策略:
1)使用定界符清楚地限定輸入的不同部分。
定界符可以是反引號、引號等等,核心思想是要清晰地標識輸入的不同部分,有助于模型理解和處理輸出。定界符就是為了讓模型明確知道,這是一個獨立的部分,它能夠有效避免“提示注入”。所謂提示注入,是指在一些用戶新添加輸入的情況下,可能誤產生一些沖突的指令,導致結果不對。

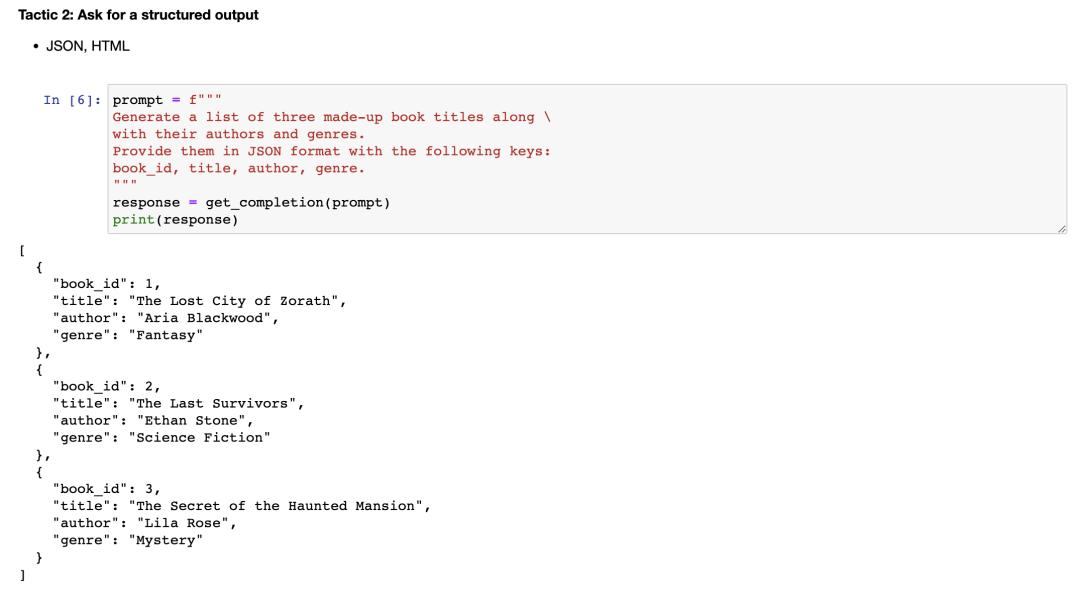
2)要求結構化輸出:為了使解析模型輸出更容易,可以請求結構化輸出。
在提示詞中,你可以明確:生成三個虛構的圖書標題,以及它們的作者和流派,使用以下格式提供:書籍ID、標題、作者和流派。
3)要求模型檢查是否滿足條件。
如果任務有假設條件并且這些條件不一定被滿足,那么可以告訴模型首先檢查這些假設條件,如果不滿足則指示出來,并停止任務直接反饋,以避免意外的錯誤結果。
比如在以下例子中:我們將復制一段描述如何泡茶的段落,然后再復制提示詞,提示詞是如果文本包含一系列指示,請將這些指示重寫為以下格式,然后寫出步驟說明。如果文本不包含一系列指示,則只需寫下“未提供步驟”。

4)小批量提示:在要求模型完成實際任務之前提供執行任務的成功示例。
這個策略簡單而重要,就是我們在提示詞中,可以包含一個正確的示例。比如我們要求模型用風格一致的口吻來回答,輸入的任務是“以一致的風格回答問題”,然后提供了一個孩子和祖父之間的對話示例,孩子說:“教我什么是耐心”,祖父用類比的方式回答。
現在我們要求模型用一致的語氣來回答,當下一個問題是:“教我什么是韌性”。由于模型已經有了這個少量示例,它會用類似的語氣回答下一個任務,它會回答:“韌性就像能被風吹彎,卻從不折斷的樹”。
原則二:給模型充足的思考時間。
如果模型因急于得出錯誤的結論,而出現了推理錯誤,應該嘗試重新構造提示詞,核心思想是要求模型在提供最終答案之前,先進行一系列相關推理。這個原則下有2個策略:

1)指定完成任務的步驟:
明確說明完成任務所需的步驟,可以幫助模型更好地理解任務并產生更準確的輸出。
2)指導模型(在急于得出結論之前)制定自己的解決方案:
明確指導模型在做出結論之前,自行推理出解決方案,可以幫助模型更準確地完成任務。
附加討論:如何看待模型的局限性?
目前大語言模型商用最大的問題是“幻覺”。因為在其訓練過程中,大模型被暴露于大量知識之中,但它并沒有完美地記憶所見到的信息,也并不清楚知識邊界在哪里。這意味著大模型可能會嘗試回答所有問題,有時會虛構出來一些聽起來很有道理,但實際上不正確的東西。
一種減少幻覺的策略是,首先要求大語言模型從文本中,找到所有相關的部分,然后要求它使用那些引文來回答問題,并將答案追溯回源文件,這種策略可以減少幻覺的發生。
今天這篇文章比較實操,我們通過2個案例(一個純文本、一個通過編程),來解釋了 (提示工程)一些更深入的應用。
像GPT-3.5、GPT-4這樣的大語言模型,它什么都懂,但恰恰也是因為太廣泛,而導致如果你不給它提示的話,你得到的回答經常是車轱轆話。
這時候(提示)的重要性不言而喻,并且不僅僅是一個詞,或是一個簡單的句子,如果你想實現更復雜的功能,也同樣需要更復雜的提示詞。
也需要大家開腦洞,想出更新奇或是更適合自己的玩法,它的“獨家性”也很強。比如之前獲獎的《太空歌劇院》,作者號稱自己花了80多個小時、900多次迭代才出來這幅作品chatgpt提示詞網站,至今也拒絕共享用了什么提示詞。

當然,本身,可能只是一種階段性的需求,Sam 曾說:五年之后,可能不再需要提示工程師這個職位,因為AI會產生自我學習的能力。但不可否認的是,這個“階段性需求”,是真正助力AI切入商業各個環節的重要利器。
我們現在也不需要從零開始摸索,國內外有很多不錯的社區,大家都在交流提示詞使用心得,甚至列出了有哪些當下熱門的提示詞,我們會在文末附錄中列出。
從創業/投資角度說,如今大家都在討論應用層的機會到底在哪里,常去這些提示詞熱門網站看看,也許能從那些新發布的熱門提示詞中,找到一些應用場景的創新靈感。看得再多,不如下場一試。
附錄:一些提示詞討論網站
1、 AI 社區:
(一個海外熱門的提示詞網站,可以按熱度排序,覆蓋場景非常齊全。)

2、 on (r/):
(上的 版塊是一個非常活躍的社區,用戶可以發布和回應各種寫作提示詞。)
3、 列舉了100條最佳提示詞
(為您的工作流提供支持的100個最佳提示詞。)
4、 一個中文提示詞網站:
(可以按熱度排序,覆蓋的場景非常齊全,從寫作、編程到金融、醫療等等。)
5、 另一個中文提示詞網站:提示精靈
(小紅書文案排序最高,對提示詞有更直觀的展示。)
本文來自微信公眾號,作者:經緯創投主頁君,36氪經授權發布。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。