chatgpt優化句子指令 中科院張家俊:ChatGPT中的提示與指令學習
邁向通用性的提示學習
一、預訓練大模型的兩種方向
預訓練大模型主要是通過“預訓練+參數微調”(Pre-+Fine-)和“預訓練+提示學習”(Pre-+ )兩種方式來實現下游任務的預測。
二、預訓練+參數微調
“預訓練+參數微調”是指大模型預訓練后作為一個良好初始化的基礎模型,從結構上適配每一個下游任務,并微調大模型的參數,使得下游任務的性能達到最優。譬如以大模型適應分類任務為例子,模型的實現方式是在預訓練模型的最后一個節點增加一個簡單的分類網絡(),在訓練過程中,不僅去更新分類網絡的參數,也去更新整個預訓練模型的參數。訓練完成后,模型就能更適合分類任務,不過與此同時,模型具有的通用性就變弱了。面向序列標注、文本生成任務也是采用預訓練+參數微調的方式來更新模型參數,模型的通用能力也會減弱。同樣的情況可以推廣到機器翻譯、自動問答、情感分析的任務。

圖 4 預訓練+參數微調:適應分類任務

圖 5 預訓練+參數微調:適應分序列任務

圖 6 預訓練+參數微調:適應文本生成任務

圖 7 “預訓練+參數微調”范式
從上面這些例子做個總結,預訓練+參數微調的方式能夠在特定任務取得不錯的效果,不過這種方式存在一些局限性。第一,預訓練+參數微調的方式缺乏處理通用問題的能力。第二,需要針對每種任務都獨立進行模型訓練,資源占用過多。第三,會存在過擬合的問題,因為不是所有類型的任務都有大量的標注數據,在下游任務數據少的情況存在泛化能力方面的問題。
三、預訓練+提示學習
“預訓練+提示學習”指的是先對大型模型進行預訓練,在后續的任務中保持參數不變,利用提示語的形式使預訓練模型能夠滿足各種下游任務需求。具體來說,我們會將下游任務轉換為預訓練模型的輸入輸出格式,例如文本分類、序列標注和文本生成等任務都需要將文本輸入格式化為預訓練模型的輸入格式chatgpt優化句子指令,并將預訓練模型的輸出轉換為任務需要的輸出格式,最終通過利用提示語激活大模型來完成特定任務。
我們針對幾個常見的NLP任務來描述一下預訓練+提示學習的處理過程。譬如有個文本分類場景要對“I love this film”這句評論來預測它表達的情感傾向是“”或“”。提示學習的處理辦法是在“I love this film”句子后面加個提示語“Its is”,用語言模型來預測下一個詞是什么,預測結果如果為“”或“”則可以作為最終預測結果,或者如果兩個詞都沒命中,可以通過判斷“”還是“”的概率更高,來完成整個任務的處理。其他的任務的處理過程是類似的,主要在于提示語有所區別。在處理詞性標注時,是在句子后面添加提示語“Its POS is”,然后就按照語言模型的方式生成詞性標注結果。在處理翻譯的時候,是在句子后面添加提示語“Its is”,然后語言模型會預測輸出“我真的喜歡這部電影”。

圖 8 預訓練+提示學習:分類任務適應大模型

圖 9 預訓練+提示學習:序列標注任務適應大模型

圖 10 預訓練+提示學習:文本生成任務適應大模型
四、提示語
提示語是預訓練+提示學習里面的重要要素。怎么理解提示語呢,提示語就是插入到下游任務文本輸入中的一段特殊文本,可以視為一組特殊參數,觸發預訓練大模型實現特定下游任務的同時,保持預訓練大模型訓練和測試一致。
提示語可以是離散的,也可以是連續的。離散的提示語比較常見,上面提及的提示語就是離散提示語。離散提示語的產生主要有兩種方式:人工分析特定的下游任務,總結下游任務的規律,設計適合特定下游任務的提示語;通過從文本數據中自動搜索的方式找到合適的完成特定下游任務的提示語。為每個任務每個樣本找到合適的提示語是一個巨大挑戰,不同提示語導致顯著的結果差異。
連續提示語則是在輸入文本或者模型中加入一組連續向量代表具有泛化能力的提示語。連續提示語有兩種添加方式,一種是直接在文本輸入前添加[5]chatgpt優化句子指令,一種是網絡或者每層網絡前添加連續向量表示提示語[6]。

圖 11 連續提示語
五、對比分析
我們對“預訓練+參數微調”和“預訓練+提示學習”兩種方式進行對比。
兩種方式最重要的區別是在支持下游任務的形式[7]。下圖中“預訓練+參數微調”的大模型需要針對不同任務來對參數進行調整,“預訓練+提示學習”只需要通過設計提示信息來修改輸入模式,使得讓它具有完成下游任務的能力。

圖 12 “預訓練+參數微調” VS “預訓練+提示學習”
雖然“預訓練+提示學習”有顯著的優點,不過在2020年前相關方向的研究成果較少。這是因為之前的模型規模較小、通用性比較弱,不適合提示學習,適合參數微調。而到了2020年后,模型規模有大幅提升,微調的成本也隨之提升,同時通用性強,適合提示學習。

圖 13 從“預訓練+參數微調”到 “預訓練+提示學習”
下圖的藍線是GPT-3在45個任務上的Zero Shot性能,準確率平均在30%左右,效果還是比較弱的。這說明提示學習能夠觸發預訓練大模型完成特定任務,但是單一的外部提示信號難以最大限度地激發預訓練大模型的能力,從而高質量地完成具體任務。

圖 14 GPT-3在45個任務上的性能
從提示學習到指令學習
“預訓練+參數微調”通過具體任務的監督數據微調模型參數,能夠最大限度地激發預訓練大模型完成特定任務的能力,但是面臨數據稀缺、災難遺忘、資源浪費、通用性弱等難題。“預訓練+提示學習”通用性強,但是在具體任務上效果偏弱。所以研究者考慮更好整合兩者的優勢,讓大模型更好理解具體任務的執行意圖,所以就有了從提示學習到指令學習的過渡。“參數微調”、“提示學習”、“指令學習”的執行邏輯如下:

圖 15 大模型+指令學習
下面看一個提示學習的例子,還是以機器翻譯、問答和情感分類作為任務場景,原來是每個任務場景對應一個模型chatgpt優化句子指令,現在把所有任務的形式轉變為語言模型的形式。譬如處理翻譯任務時,把提示語的信息插入文本得到“‘I love ’的中文翻譯是”。不同的樣本可以使用不同的提示語來保證一定差異性。然后把所有任務的標注數據合并在一起,作為一個統一的任務執行參數微調。所有數據經過訓練之后得到一個新的大模型,新的大模型可以再利用提示語觸發大模型去完成特定的能力,結果是能夠支持不同任務的同時也提升了多任務的執行效果。

圖 16 “大模型+指令學習”適應下游任務

圖 17 谷歌FLAN模型
這是當時谷歌提出來FLAN的例子,左上角是預訓練+微調,左下角是提示語,右邊是FLAN的指令學習,是前兩者的結合。FLAN在數十個任務上微調,發現它在未見的任務上也有預測能力。舉例來說,FLAN在對常識推理、翻譯等任務進行微調后,會發現訓練好的模型會在自然語言推斷任務上具備不錯的預測效果。所以FLAN在62個數據集40多個任務上進行了訓練,任務包含理解和生成兩種形態。實驗結果發現當參數達到百億規模以上,幾十個任務的聯合指令學習就可以解決未知的任務。

圖 18 FLAN展現的未知任務的預測能力

圖 19 FLAN使用的文本任務數據集

圖 20 百億參數規模模型多任務聯合學習可以解決未知任務
FLAN的重大發現對后續的工作起到了指導作用。在此基礎上,的前身 GPT收集了API指令,這樣它的指令 類型更豐富,覆蓋的范圍越大,在此基礎上的訓練更觸發了它的通用能力。
大語言模型的相關探索和實踐
一、如何尋找最佳的提示語
上文提示學習的內容提到,提示語對預測效果有顯著影響。下面的例子展示了在處理同樣的文本翻譯時,采用了不同的提示詞(“中文翻譯是什么”和“用中文怎么說”),返回的結果差異非常大。此時如何提升模型效果的問題可轉化為,如何找到不同問題的最佳提示語,有沒有一種方法自動學習提示語。

圖 21 不同提示語對文本翻譯結果的影響
二、樣本級提示學習方法
針對上述問題,我們提出一種樣本級提示學習方法[10],為每個樣本學習最合適的提示語。執行的方式為,來了新的樣本時,模型會結合輸入的提示語和文本,根據相關性去搜索最相關的提示語,作為語言模型的輸入。這種方法的優勢是最大限度地建模了不同樣本的獨特性,相比于相同的提示語取得更好的性能提升,不過存在的不足之處是未考慮樣本間的共性,也即忽略了不同的樣本實際上屬于同一種任務的事實。
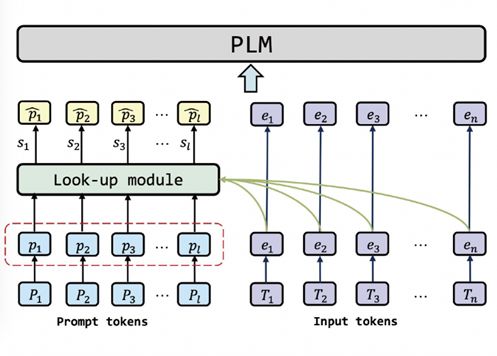
圖 22 樣本級提示學習方法
三、統一提示學習方法
鑒于樣本級提示學習方法只考慮樣本、沒有考慮到任務的共性,所以我們進一步提出了統一提示語學習的方法[11],可以同時建模任務級的信息和樣本級的信息。它的處理辦法是為每個任務學習一個提示,為任務中的每個樣本學習一個提示,兩類提示信息進行融合,獲得最佳提示。下圖是統一提示學習方法的架構,灰色的部分參數不變,藍色的部分是非常小的參數量,一個是從樣本學到樣本級的參數,一個是每個任務有對應的參數。通過這個結構模型能夠判斷每個樣本應該用多少任務級的信息、多少樣本級的信息,最終為每個樣本學到最合適的提示。

圖 23 統一提示學習方法
統一提示學習方法優勢是同時結合了任務信息和樣本信息,理論上可以獲得最佳的提示信息。存在的不足是需要提前知道任務信息,需要進一步的泛化。相比之下目前在不知道請求的任務是什么的情況,也能夠感知到任務的具體類型,有較大優勢。后續研究拓展方向可以通過感知的方式判斷任務的信息,在跟任務信息已知的基礎上再去學習任務和樣本相關的泛化。
四、實驗效果
實驗結果驗證了統一提示學習方法在標準數據集上取得少樣本學習的最佳平均性能。在數據集上發現,統一提示學習方法比GPT-3在上下文推理能力能力更優(單句子任務的平均任務得分分別為83.2和70.0,句子對相關任務的平均得分為72.0和49.8),這說明了學習提示對提升模型效果非常有效,如何找到最佳提示語非常關鍵。

圖 24 統一提示學習方法在標準數據集單句子任務上的效果

圖 25 統一提示學習方法在標準數據集雙句子任務上的效果
開放性問題思考
一個月前寫了《八個技術問題的猜想》,后來一直在做模型探索,整理了一些開放性問題與觀眾讀者探討:
第一,實踐發現數據不僅僅決定模型性能,還能極大影響模型訓練過程的成敗,其中的原因是什么。Meta去年發布幾個模型,在訓練過程中失敗掛掉了二十多次,每一次數據會影響數據的訓練是否成功。
第二,能力涌現是如何發生的?為什么會在百億參數規模以上才會體現出來?或者并非涌現,只是模型規模測試不夠連續。
第三,中文等語言的數據占比非常少,例如只有不到5%,而模型的中文表現卻非常好?能力遷移是如何發生的。
第四,大模型的能力能否蒸餾到小模型。
第五,作為黑盒的通用大模型似乎與人腦有相似之處,未來是否可以采用腦科學研究范式研究大模型。
參考文獻
[1] A, N, N, et al. is all you need[J]. in , 2017, 30.
[2] Wei J, M, Zhao V Y, et al. are zero-shot [J]. :2109., 2021.
[3] J, F, P, et al. [J]. :1707., 2017.
[4] Von L, S, K, et al. –A and of into [J]. IEEE on and Data , 2021, 35(1): 614-633.
[5] B, Al-Rfou R, N. The of for - [J]. :2104., 2021.
[6] Li X L, P. -: for [J]. :2101., 2021.
[7] Liu P, Yuan W, Fu J, et al. Pre-, , and : A of in [J]. ACM , 2023, 55(9): 1-35.
[8] Wei J, M, Zhao V Y, et al. are zero-shot [J]. :2109., 2021.
[9] L, Wu J, X, et al. to with [J]. in , 2022, 35: -.
[10] Jin F, Lu J, J, et al. - for and [J]. :2201., 2022.
[11] Jin F, Lu J, J,et al. pre- few-shot . 2023.
相關文章:“翻譯技術沙龍”第十三次活動 ——計算機輔助翻譯與譯后編輯 NLP 是一個力氣活:再論成語不是問題 如何計算兩個文檔的相似度全文文檔 AI 2018 細粒度用戶評論情感分析
文章導航
“國產類 ”所存在的差距與挑戰-專家圓桌
新浪張俊林:大語言模型的涌現能力——現象與解釋
免責聲明:本文系轉載,版權歸原作者所有;旨在傳遞信息,不代表本站的觀點和立場和對其真實性負責。如需轉載,請聯系原作者。如果來源標注有誤或侵犯了您的合法權益或者其他問題不想在本站發布,來信即刪。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。