chatgpt應(yīng)用程序 ChatGPT火了,生成式AI在全球都有哪些場(chǎng)景和應(yīng)用?
文丨江志強(qiáng)( AI 創(chuàng)始人)
上線短短5天,用戶量破百萬,兩個(gè)月余時(shí)間,月活躍用戶數(shù)預(yù)計(jì)已達(dá)1億——的火爆,意味著我們迎來了生成式AI的大浪潮。
人工智能(AI)是一個(gè)廣泛的術(shù)語,指的是任何能夠進(jìn)行智能行為的技術(shù)。生成式AI是其中一種特定類型的AI,專注于生成新內(nèi)容,如文本、圖片、音樂等。
回顧2022年的AI格局,正是由生成式AI的大模型( )所驅(qū)動(dòng)。這些大模型正在迅速從研究實(shí)驗(yàn)室走出來,撲向真實(shí)世界的各個(gè)場(chǎng)景與應(yīng)用,2023年影響的層面會(huì)更大,發(fā)展的速度會(huì)更快。另外兩個(gè)由大型語言模型 (LLM, ) 技術(shù)驅(qū)動(dòng)的新興領(lǐng)域,則是幫助人做決策的AI代理(游戲,機(jī)器人等), 以及應(yīng)用在科學(xué)領(lǐng)域的AI for 。
以下是筆者總結(jié)的全球范圍內(nèi)生成式AI的16個(gè)方向和場(chǎng)景應(yīng)用,大致可以分為從文本轉(zhuǎn)圖片、從文本轉(zhuǎn)音樂、文本聊天和溝通、文本驅(qū)動(dòng)機(jī)器人、文本轉(zhuǎn)視頻以及AI做科研等幾大類。

01 Text-to- 前驅(qū)者 -2
-2 是擴(kuò)散模型 ( ) 比較具代表性的大模型之一,也是由公司所開發(fā)的,能根據(jù)文本生成逼真的高分辨率的高質(zhì)量圖像,用于圖像生成。它是基于原先DALL-E(原先用的是模型)的版本來改進(jìn),具有更高的生成質(zhì)量和更大的模型尺寸,推動(dòng)AI在全球的藝術(shù)革命。
-2的核心主要包括CLIP模型和模型;CLIP( - Pre-)是通過將文本與圖像進(jìn)行對(duì)比的預(yù)訓(xùn)練大模型,學(xué)習(xí)文本與圖像之間的關(guān)系,而負(fù)責(zé)聽CLIP的引導(dǎo)生產(chǎn)圖片。
-2目前還是閉源的,用戶可以通過它的WEB界面或API來使用它。

02 開源的 橫空出世
繼-2之后繼續(xù)顛覆藝術(shù)的革命、也引起技術(shù)界轟動(dòng)的 (文中簡(jiǎn)稱SD),是一個(gè)基于 (潛在擴(kuò)散模型)來實(shí)現(xiàn)文字轉(zhuǎn)圖片的大模型,類似-2和谷歌的等類似技術(shù),SD可以在短短幾秒鐘內(nèi)生成清晰度高,還原度佳、風(fēng)格選擇較廣的AI圖片,這讓SD在同類技術(shù)中脫穎而出。
SD最大的突破是任何人都能免費(fèi)下載并使用其開源代碼,因?yàn)槟P痛笮≈挥袔讉€(gè)G而已!因此在短時(shí)間內(nèi) 網(wǎng)站上有100萬次模型的下載,也是破了網(wǎng)站的歷史記錄。這讓AI圖片生成模型不再只是業(yè)內(nèi)少數(shù)公司自我標(biāo)榜技術(shù)能力的玩物,許多創(chuàng)業(yè)公司和研究室正在快速進(jìn)入,集成SD模型來開發(fā)各種不同場(chǎng)景的應(yīng)用,包括我們 AI公司。
SD以掩耳盜鈴之勢(shì)迅速迭代,開源社區(qū)也在不斷改進(jìn)SD。在SD v2.0上線不到兩周時(shí)間,就迅速更新到v2.1版本。相比于前一版本,主要放寬了內(nèi)容過濾的限制,減少了訓(xùn)練的誤傷,也有這三大特色:更高質(zhì)量的圖片、圖像有了景深、負(fù)向文本的技巧更好的約束AI生成的隨機(jī)性,也支持在單個(gè)GPU上來運(yùn)行。


SD官網(wǎng)上寫著 “by the , for the ” 的使命,與熱烈追求民主化的開源,已被證明是改寫了 AI 賽道的游戲規(guī)則,同時(shí)也讓 AI公司在不到兩年的時(shí)間內(nèi)迅速變成獨(dú)角獸公司,快速融資了1億美金。高質(zhì)量!免費(fèi)開源!更新快!這幾個(gè)關(guān)鍵詞就已經(jīng)決定了 的出世必定絕不平凡!借助這一突破性技術(shù)嘗試給你的寵物照片變個(gè)身吧!?

AI公司的產(chǎn)品底層就集成了SD的各個(gè)版本模型,雖然做成應(yīng)用,我們?cè)谀P偷讓雍彤a(chǎn)品應(yīng)用中間層還是要做非常多的工作,不過我們非常看好 AI這家公司, 也期待他們下一步能繼續(xù)驚世駭俗。
03 谷歌兩個(gè)未開源 Text-to- 擴(kuò)散模型
2022年 AI還有兩個(gè)-to-text模型。和分別是擴(kuò)散模型 ( ) 和自回歸模型 (Auto- ),兩者不同但互補(bǔ),代表了谷歌兩個(gè)不同探索方向,模型都沒有開源或可以集成的API,所以 團(tuán)隊(duì)無法動(dòng)手研究,但論文仍是富有有趣的見解。不管這些大模型再怎么厲害chatgpt應(yīng)用程序,對(duì) AI這樣做產(chǎn)品應(yīng)用的公司而言,“只能仰望和遠(yuǎn)觀,不能褻玩焉”。
大模型網(wǎng)址: ..

不同于其他已知的文本出圖的大模型,其更注重深層次的語言理解。的預(yù)訓(xùn)練語言模型(T5-XXL)的訓(xùn)練集包含的純文本語料,在文本理解能力上會(huì)比有限圖文訓(xùn)練的效果更強(qiáng)。的工作流程為:在輸入后,如“一只戴著藍(lán)色格子貝雷帽和紅色波點(diǎn)高領(lǐng)毛衣的金毛犬”(A dog a blue and red ),先使用谷歌自研的T5-XXL編碼器將輸入文本編碼為嵌入,再利用一系列擴(kuò)散模型,從分辨率 64×64 → 256×256 → 1024×1024的過程來生成圖片。結(jié)果表明,預(yù)訓(xùn)練大語言模型和多聯(lián)擴(kuò)散模型在生成高保真圖片方面效果很好。

大模型網(wǎng)址: ..

是一種自回歸文本生成圖片模型( Auto- Text-to- ),其將文本到圖片的生成視為序列到序列的建模問題,類似于機(jī)器翻譯,這使其受益于大語言模型的進(jìn)步。在輸出圖片序列后,使用圖像標(biāo)記器 ViT-將圖片編碼為離散序列,并利用其重建圖片序列的能力,使其成為高質(zhì)量、視覺多樣化的圖像。
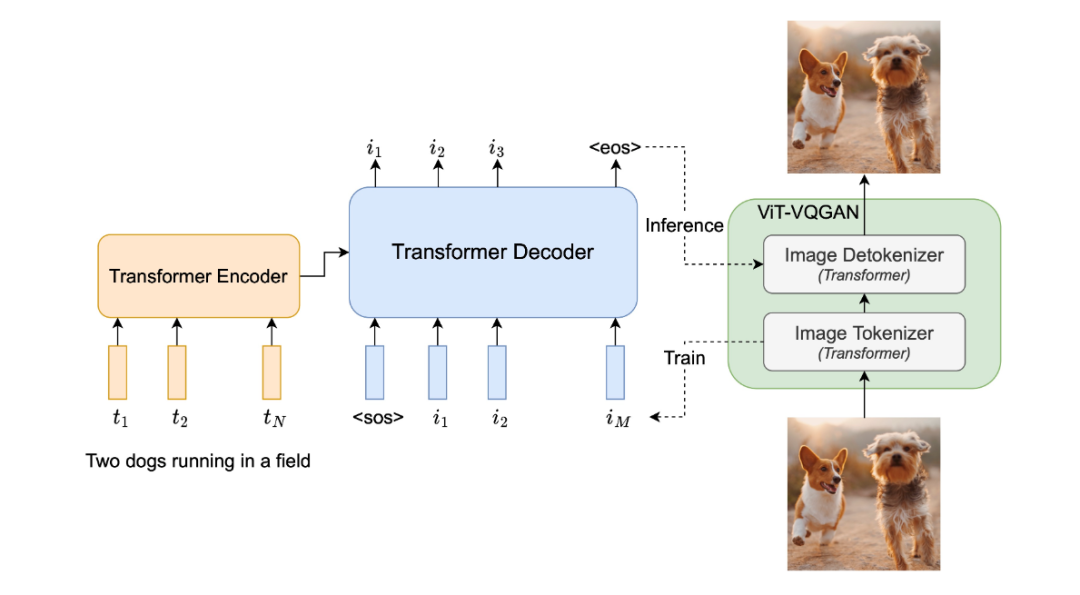
04 將顛覆搜索并沖擊許多領(lǐng)域的!
!史上唯一5天內(nèi)獲得100萬用戶的應(yīng)用,兩個(gè)月時(shí)間用戶量達(dá)1億,打破上個(gè)記錄保持者——用9個(gè)月時(shí)間將用戶量沖上1億的。的快速發(fā)展與日益智能的知識(shí)助理角色,挑戰(zhàn)了像谷歌這樣的傳統(tǒng)信息搜索巨頭的產(chǎn)品形態(tài)與商業(yè)模式。
讓機(jī)器學(xué)習(xí)如何更好地理解人類語言,從而更好地回答問題,更好地跟人類寫作,甚至近一步啟發(fā)人類的創(chuàng)造力。本次發(fā)布的是基于GPT-3的微調(diào)版本,即GPT-3.5。它使用了一種新技術(shù)RLHF(“人類反饋強(qiáng)化學(xué)習(xí)”)。相比GPT-3,的主要提升點(diǎn)在于記憶能力,可實(shí)現(xiàn)高度擬人化的連續(xù)對(duì)話和問答,也可以按輸入的具體指令產(chǎn)出特定的文本格式。
在各種社區(qū)的討論中被總結(jié)出幾十種內(nèi)容產(chǎn)出的的場(chǎng)景與用例,比如:投資研究報(bào)告、工作周報(bào)、論文摘要、合同文本、招聘說明書、指定計(jì)算機(jī)語言的代碼等等。會(huì)關(guān)注 AI 微信公眾號(hào),我們后續(xù)的選題規(guī)劃,會(huì)整理出一篇文章,總結(jié)出幾十種的使用方式。
當(dāng)然,也有人工智障的時(shí)候,比如:對(duì)人類的知識(shí)只截止到2021年底,所以實(shí)時(shí)信息的搜索還是得借助搜索引擎;數(shù)學(xué)不好;或是如果問它不合邏輯的問題,它會(huì)被繞暈。
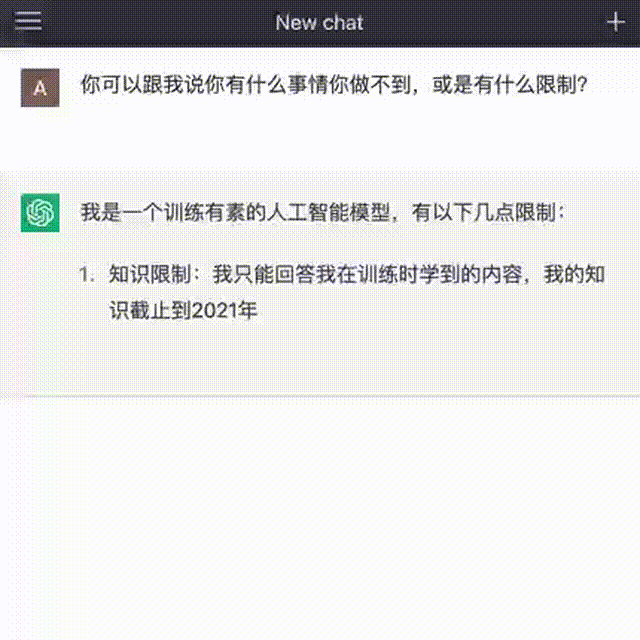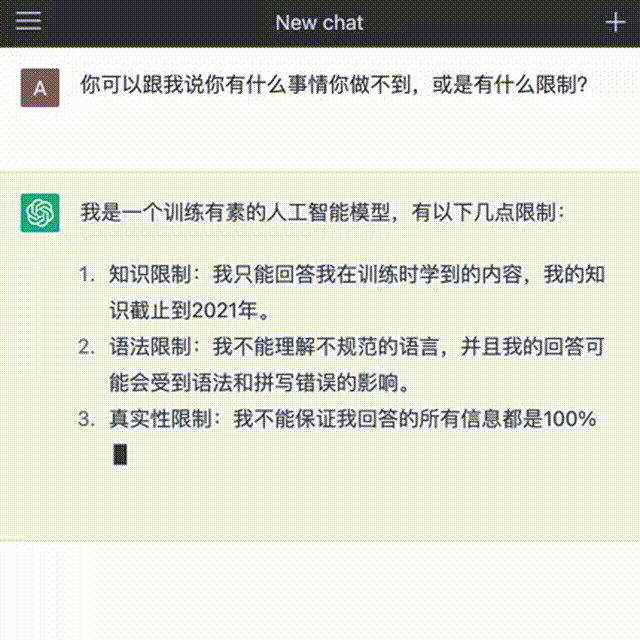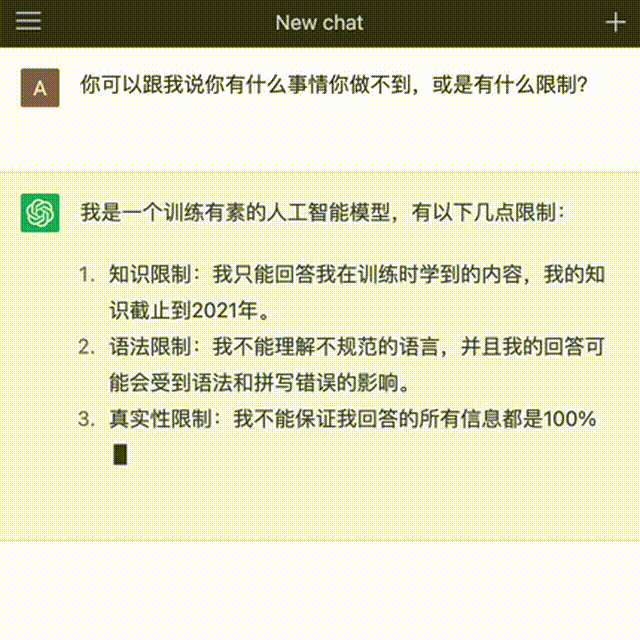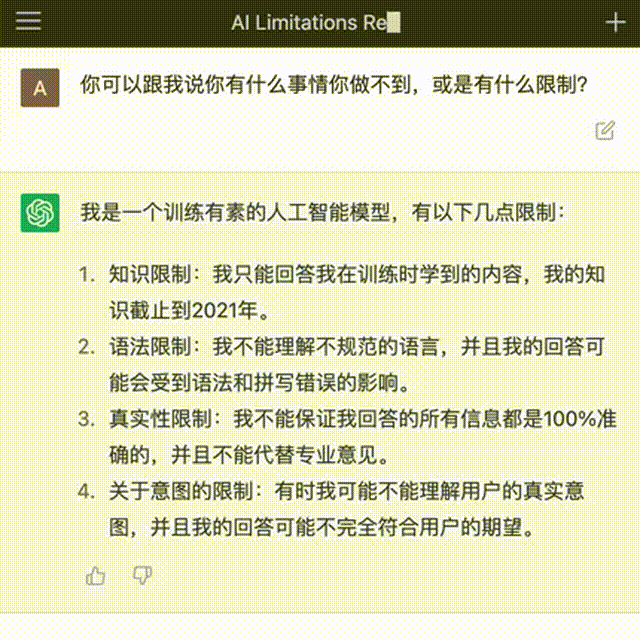
目前 的極致能力展現(xiàn)在:通過美國(guó)醫(yī)療專業(yè)執(zhí)照的考試,通過美國(guó)知名商學(xué)院沃頓的MBA考試等接近人的水平。某種意義上,越來越像一個(gè)“真實(shí)的人”,只要算力足夠強(qiáng)大,它與人類的互動(dòng)越多,就將“成長(zhǎng)”越快,也能具備更好的邏輯“思考”結(jié)果。只要時(shí)間足夠長(zhǎng),人工智能的能力將持續(xù)提升和擴(kuò)展。因此,也引發(fā)了學(xué)術(shù)界的抗?fàn)帯⑴c法律與倫理相關(guān)問題的諸多討論與隱憂。
學(xué)術(shù)界反抗的力量,包括美國(guó)斯坦福團(tuán)隊(duì)推出,阻止學(xué)生用AI寫作業(yè)。另一個(gè)由一位華裔學(xué)生 創(chuàng)建的,用于檢測(cè)文本是否由人工智能寫作出來的。它使用兩個(gè)指標(biāo)"困惑度"和"突發(fā)性"來衡量文本的復(fù)雜度,如果對(duì)文本感到困惑chatgpt應(yīng)用程序,則其復(fù)雜度較高,更判定可能是人工所編寫的。
是個(gè)超級(jí)重磅的話題,2023 年對(duì)未來的揣想,我們?cè)诤罄m(xù)的文章中,再來繼續(xù)探討吧~
05 用文本來驅(qū)動(dòng)機(jī)器人Text-to- !
如何給GPT手臂和腿,讓它們能夠清理你整潔的廚房?不像NLP 自然語言處理的人工智能技術(shù),機(jī)器人模型需要與物理世界互動(dòng)。今年,大型的預(yù)訓(xùn)練模型終于開始解決機(jī)器人技術(shù)中困難的多模態(tài)問題。機(jī)器人技術(shù)中的任務(wù)規(guī)范有多種形式,如模仿一次性演示、遵循語言指示和達(dá)到視覺目標(biāo)。它們通常被認(rèn)為是不同的任務(wù),由專門的模塊來處理。
由英偉達(dá)等機(jī)構(gòu)研發(fā)的VIMA用多模態(tài)的提示來表達(dá)廣泛的機(jī)器人操縱任務(wù)。如此一來,它就可以用單一的模塊來處理文本和視覺標(biāo)記的提示,并自動(dòng)輸出運(yùn)動(dòng)動(dòng)作。為了訓(xùn)練和評(píng)估VIMA,他們開發(fā)了新的模擬基準(zhǔn),其中有數(shù)千個(gè)程序化生成的任務(wù)和60萬以上專家軌跡用于模仿學(xué)習(xí)。VIMA在模型容量和數(shù)據(jù)大小方面都實(shí)現(xiàn)了強(qiáng)大的可擴(kuò)展性。在相同的訓(xùn)練數(shù)據(jù)下,它在最難的zero-shot泛化設(shè)置中優(yōu)于先前的SOTA方法,任務(wù)成功率高達(dá) 2.9倍。在訓(xùn)練數(shù)據(jù)減少10倍的情況下,VIMA的表現(xiàn)仍然比競(jìng)爭(zhēng)方法好2.7倍。

與VIMA類似,的研究人員發(fā)布了RT-1,一種多模態(tài)機(jī)器人變換器。它將機(jī)器人的輸入和輸出動(dòng)作(如相機(jī)圖像、任務(wù)指令和電機(jī)命令)標(biāo)記化,以便在運(yùn)行時(shí)進(jìn)行有效的推理。RT-1使用13個(gè) (EDR)機(jī)器人收集的數(shù)據(jù)進(jìn)行訓(xùn)練,包括了700多項(xiàng)任務(wù)、13萬時(shí)間片段。與之前的技術(shù)相比,RT-1可以對(duì)新的任務(wù)、環(huán)境和物體表現(xiàn)出明顯改善的 zero-shot 泛化能力。

06 萬眾期待的Text-to-
在文本生成視頻領(lǐng)域,我們想向大家介紹三款頭部的研究,他們分別來自于 Meta, 和 。
如果你是一名創(chuàng)作者,當(dāng)你將文本轉(zhuǎn)化成圖片后,一個(gè)很自然的想法是:希望能讓圖片動(dòng)起來,形成一個(gè)視頻,從而展示更豐富的細(xì)節(jié)。Meta公司研究的“Make-A-” 中的Text-to-模型就完成了這樣一件事:當(dāng)輸入小馬在喝水時(shí),模型就會(huì)根據(jù)文字生成一個(gè)小馬喝水的視頻。


Text-to-模型采用無監(jiān)督學(xué)習(xí)的方法生成視頻數(shù)據(jù)集,并且通過插值網(wǎng)絡(luò)進(jìn)行調(diào)整,他的模型結(jié)構(gòu)可以概括如下:

無獨(dú)有偶,谷歌也發(fā)布了自己的文字生成視頻的產(chǎn)品 : 基于 (擴(kuò)散模型)的視頻生成模型。該模型最終生成128張圖片,并在每秒內(nèi)播放24張,最終形成5.8s的高清視頻。
相關(guān)的頭部模型還有: 使用 (因果模型)來通過文字生成視頻,他們的模型考慮了時(shí)間變量,因此可以生成任意時(shí)長(zhǎng)的視頻。
短視頻是互聯(lián)網(wǎng)巨頭的必爭(zhēng)之地,所以Text-to-的發(fā)展也備受矚目,不過 AI觀點(diǎn)是chatgpt應(yīng)用程序,這些巨頭的技術(shù)研究不見得愿意開源出來,因?yàn)闋可娴骄薮蟮纳虡I(yè)利益。另外,這個(gè)領(lǐng)域可能也不是小創(chuàng)業(yè)團(tuán)隊(duì)的事,因?yàn)榧幢隳阌泻玫囊曨l預(yù)訓(xùn)練大模型,視頻素材的數(shù)據(jù)取得與訓(xùn)練,是一個(gè)成本高昂的問題。
07 Tune-A-調(diào)整視頻生成
Tune-A-最初是由在2023年1月發(fā)表的一篇論文中提出的,展示了僅使用文本提示即可生成簡(jiǎn)單的 視頻。這是一種使用單個(gè)文本-視頻對(duì)進(jìn)行模型微調(diào)的文本生成視頻生成方法,它是從預(yù)訓(xùn)練 Text-to-imae 的擴(kuò)散式模型進(jìn)行擴(kuò)展而來的。訓(xùn)練過程中僅更新了注意力塊中的投影矩陣。Tune-A-支持在個(gè)性化的 訓(xùn)練與模型微調(diào),以及在 and 數(shù)據(jù)集上進(jìn)行視頻調(diào)整。
這種文本到視頻生成方法最近被新加坡國(guó)立大學(xué)的 Show Lab 的研究人員進(jìn)一步改進(jìn),解決了單個(gè)文本-視頻對(duì)訓(xùn)練的問題。通過使用自定義的稀疏因果關(guān)注機(jī)制( - ),Tune-A-將空間自注意力( self-)擴(kuò)展到時(shí)空域( ),使用預(yù)訓(xùn)練的文本到圖像擴(kuò)散模型。
08 Text-to-3D 恐怕還要再等等
從設(shè)計(jì)創(chuàng)新產(chǎn)品到電影和游戲中令人驚嘆的視覺效果,3D建模將是創(chuàng)意AI領(lǐng)域?qū)崿F(xiàn)從文本到想法的下一步。2022年已經(jīng)出現(xiàn)了幾個(gè)原始但極具潛力的3D生成模型!
: AI 的,可將文本轉(zhuǎn)換為3D生成的圖像。它將文中上述提過的文本出圖 大模型與NeRF的3D功能結(jié)合在一起,生成適用于AR項(xiàng)目或作為雕塑基礎(chǔ)網(wǎng)格的質(zhì)量較高的紋理3D模型,可以從任意角度查看,并可根據(jù)不同的照明條件重新照明。 AI還可以根據(jù)生成圖像模型的2D圖像生成3D模型。

英偉達(dá)公司則有兩項(xiàng)重要的研究成果:和,目標(biāo)是通過允許用戶從文本生成3D模型,使3D內(nèi)容創(chuàng)建更加容易。是一種高分辨率的文本到3D內(nèi)容創(chuàng)建方法,它采用內(nèi)容從粗略到精細(xì)的漸進(jìn)過程,利用低分辨率和高分辨率的擴(kuò)散先驗(yàn)來學(xué)習(xí)目標(biāo)內(nèi)容的3D表現(xiàn)。據(jù)媒體報(bào)道,它比的快2倍,僅需40分鐘即可創(chuàng)建高質(zhì)量的3D網(wǎng)格模型。是一個(gè)AI模型,結(jié)合了自然語言(NLP)和計(jì)算機(jī)視覺技術(shù),用文本描述生成逼真的3D對(duì)象。這使用戶可以快速創(chuàng)建逼真的3D模型,無需任何先前的建模技能。


AI認(rèn)為Text-to-3D全球都在比較早期的階段, 因?yàn)橐矝]有開源,所以業(yè)界無法研究和參與。我們?cè)?jīng)跟其他AI創(chuàng)業(yè)者交流,他們用 和Nerf放在一起做實(shí)驗(yàn),有點(diǎn)樣子,但是最大的障礙還是全球領(lǐng)域能做訓(xùn)練的3D圖像數(shù)據(jù)少之又少,而用技術(shù)的方法制造AI訓(xùn)練用的數(shù)據(jù)成本也很高,我們?nèi)孕枘托牡群颉?/p>
09 AI自己玩 !?
“我的世界”這個(gè)游戲絕對(duì)是一個(gè)完美的通用智能測(cè)試平臺(tái),因?yàn)椋?/p>
2022年我們看到一些實(shí)驗(yàn)室和公司使用大模型來訓(xùn)練AI 在中執(zhí)行各種任務(wù)的成功案例。這些大模型可以建造城堡,挖掘礦物,甚至與其他玩家交互。

為了利用互聯(lián)網(wǎng)上大量可用的未標(biāo)記視頻數(shù)據(jù),開發(fā)了一種視頻預(yù)訓(xùn)練 (VPT) 算法。首先向游戲商家收集2,000小時(shí)的少量數(shù)據(jù)集,其數(shù)據(jù)集記錄游戲視頻,也記錄了玩家采取的行動(dòng)(按鍵操作和鼠標(biāo)移動(dòng))。利用這些數(shù)據(jù),訓(xùn)練出一個(gè)逆動(dòng)力學(xué)模型(IDM)以 “預(yù)測(cè)” 視頻中每個(gè)步驟所采取得動(dòng)作。通過使用經(jīng)過訓(xùn)練的 IDM模型來標(biāo)記更多的在線視頻數(shù)據(jù),并通過行為克隆來建立學(xué)習(xí)的行為。AI通過觀看70,000小時(shí)視頻的大數(shù)據(jù)量就可以被訓(xùn)練自己玩。

還開發(fā)了一個(gè)名為 的AI代理,可以根據(jù) 中的文字提示執(zhí)行操作,并獲得了國(guó)際機(jī)器學(xué)習(xí)會(huì)議的杰出論文獎(jiǎng)。微軟也有一個(gè)新的AI “代理”,它在游戲內(nèi)運(yùn)行 。
10 AI 發(fā)現(xiàn)新材料
AI在材料科學(xué)領(lǐng)域的應(yīng)用正在快速發(fā)展,其中AI發(fā)現(xiàn)新材料是一項(xiàng)重要的技術(shù)。這項(xiàng)技術(shù)包含了數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)兩個(gè)步驟。數(shù)據(jù)挖掘通過從大量數(shù)據(jù)中提取有用信息來實(shí)現(xiàn)。AI通過對(duì)數(shù)據(jù)的分析,提取有關(guān)材料性能的信息。機(jī)器學(xué)習(xí)是通過利用算法從數(shù)據(jù)中學(xué)習(xí)來實(shí)現(xiàn)的。在這個(gè)步驟中,AI利用算法預(yù)測(cè)新材料的性能。這個(gè)可能更偏向 AI。
今年,發(fā)布了一種名為" "的模型,該模型可以根據(jù)給定的物理和化學(xué)性質(zhì)生成新的材料結(jié)構(gòu)。這項(xiàng)技術(shù)有望在未來幫助材料科學(xué)家發(fā)現(xiàn)更高性能的材料。然而,也存在一些挑戰(zhàn),其中一個(gè)是數(shù)據(jù)缺乏。這項(xiàng)技術(shù)需要大量數(shù)據(jù)來做出準(zhǔn)確的預(yù)測(cè),如果數(shù)據(jù)不足,AI可能會(huì)做出不準(zhǔn)確的預(yù)測(cè)。另一個(gè)挑戰(zhàn)是材料的復(fù)雜性。由于材料是復(fù)雜的系統(tǒng),AI可能無法準(zhǔn)確預(yù)測(cè)材料在不同環(huán)境中的性能。

11 AI 助力醫(yī)學(xué)研究
旗下公司Deep Mind的 (2021) ,是全球第一個(gè)能夠準(zhǔn)確預(yù)測(cè)蛋白質(zhì)3D結(jié)構(gòu)的模型。同年7月,Deep Mind宣布了“蛋白質(zhì)宇宙”—— 擴(kuò)大 的蛋白質(zhì)數(shù)據(jù)庫至200M種結(jié)構(gòu),這簡(jiǎn)直是非常珍貴的科學(xué)瑰寶!AI在醫(yī)學(xué)研究領(lǐng)域的應(yīng)用(AI for )也在迅速發(fā)展,特別是公司的CEO - Sam 接下來也非常看好的領(lǐng)域。

2022年發(fā)布了一種名為 "" 的模型,該模型可以根據(jù)病人的病史和影像學(xué)數(shù)據(jù)生成診斷和治療建議。這項(xiàng)技術(shù)有望幫助醫(yī)生更快更準(zhǔn)確地診斷疾病,并且還可以幫助研究人員發(fā)現(xiàn)新的治療方法。同年,費(fèi)城生物醫(yī)學(xué)工程卓克索大學(xué)的一項(xiàng)研究發(fā)現(xiàn),可以通過和人類的對(duì)話,幫助發(fā)現(xiàn)是否有阿爾茨海默氏病的早期癥狀,準(zhǔn)確率達(dá)80%,高于使用傳統(tǒng)方法的74.6%的正確率,從而及時(shí)提示患病風(fēng)險(xiǎn)。文章前面提到過,的極致能力已經(jīng)展現(xiàn)在可以通過美國(guó)醫(yī)療專業(yè)執(zhí)照的考試。
12 AI可以通過網(wǎng)絡(luò)視頻學(xué)習(xí)嗎?——VPT(“視頻預(yù)訓(xùn)練”)模型
AI 可以學(xué)習(xí)人類復(fù)雜的動(dòng)作嗎?可以!Jeff 的團(tuán)隊(duì)發(fā)布了VPT(“視頻預(yù)訓(xùn)練”)模型,它甚至可以通過學(xué)習(xí)自己玩“我的世界”()!在“我的世界”中,一個(gè)人制作鉆石工具需要完成2萬多個(gè)動(dòng)作,花費(fèi)20分鐘,VPT通過學(xué)習(xí)記錄了人們點(diǎn)擊鍵盤鼠標(biāo)的操作,居然學(xué)會(huì)了自己在我的世界中完成這些動(dòng)作。
換句話說,只要知道了鼠標(biāo)和鍵盤的點(diǎn)擊移動(dòng)順序,VPT可以通過 (逆向動(dòng)力模型)學(xué)習(xí)一切我們認(rèn)為只有人類才能做到的復(fù)雜動(dòng)作,比如如果我們可以準(zhǔn)確記錄數(shù)字繪畫家在電子屏幕上的操作順序,那么模型也可以模仿數(shù)字繪畫家繪制一幅美麗的日落,VPT為AI通過互聯(lián)網(wǎng)上的視頻來學(xué)習(xí)鋪平了道路!
13 AI 代理在談判上的突破
多年來,人們提出了許多用于外交的人工智能方法,主要依賴手工制定的協(xié)議和基于規(guī)則的系統(tǒng),但遠(yuǎn)遠(yuǎn)落后于人的表現(xiàn)(無論有無溝通)。
Meta公司的人工智能 是第一個(gè)在外交游戲中達(dá)到人類水平表現(xiàn)的AI代理,在游戲《外交》中,具有對(duì)他人的信仰、目標(biāo)和意圖進(jìn)行推理的能力,可以通過表現(xiàn)同理心、使用人類語言交流并建立人際關(guān)系,同時(shí)能夠有效地說服甚至欺騙,來達(dá)到在游戲中獲勝的目的。
與此同時(shí),公司也宣布了他們的外交游戲 AI 代理。試想,如果與 的AI對(duì)戰(zhàn)會(huì)發(fā)生什么?

14 -to-text 音頻生成文本
是由開發(fā)的一個(gè)大型開源音頻識(shí)別模型。它在英語的語音識(shí)別方面達(dá)到了接近人類水平的準(zhǔn)確性和魯棒性(在語音識(shí)別中,“魯棒性”通常指一個(gè)模型的能力,即在嘈雜或有干擾的環(huán)境下識(shí)別語音的準(zhǔn)確性和可靠性)。與其他模型不同的是,使用了更大以及更多樣的訓(xùn)練數(shù)據(jù)集。它使用網(wǎng)絡(luò)上的共680,000小時(shí)的音頻數(shù)據(jù)進(jìn)行訓(xùn)練,這些數(shù)據(jù)是多語言和多任務(wù)的,使得除了能將英語轉(zhuǎn)成英文,還能將幾乎所有語種聲音轉(zhuǎn)成對(duì)應(yīng)文字以及翻譯成英語。
提供了多種大小的英語/多語言模型,使得開發(fā)者能夠在識(shí)別速度和識(shí)別質(zhì)量中權(quán)衡。對(duì)于英語任務(wù),開發(fā)者使用較小的模型便可達(dá)到良好的效果,識(shí)別速度甚至可以達(dá)到實(shí)時(shí)處理的效果。如果使用大模型,識(shí)別準(zhǔn)確性則可以說超越所有現(xiàn)有商業(yè)公司產(chǎn)品。對(duì)于漢語任務(wù),開發(fā)者必須使用大模型才能達(dá)到較準(zhǔn)確的識(shí)別,識(shí)別速度與中國(guó)商業(yè)公司的產(chǎn)品相比有一定差距。

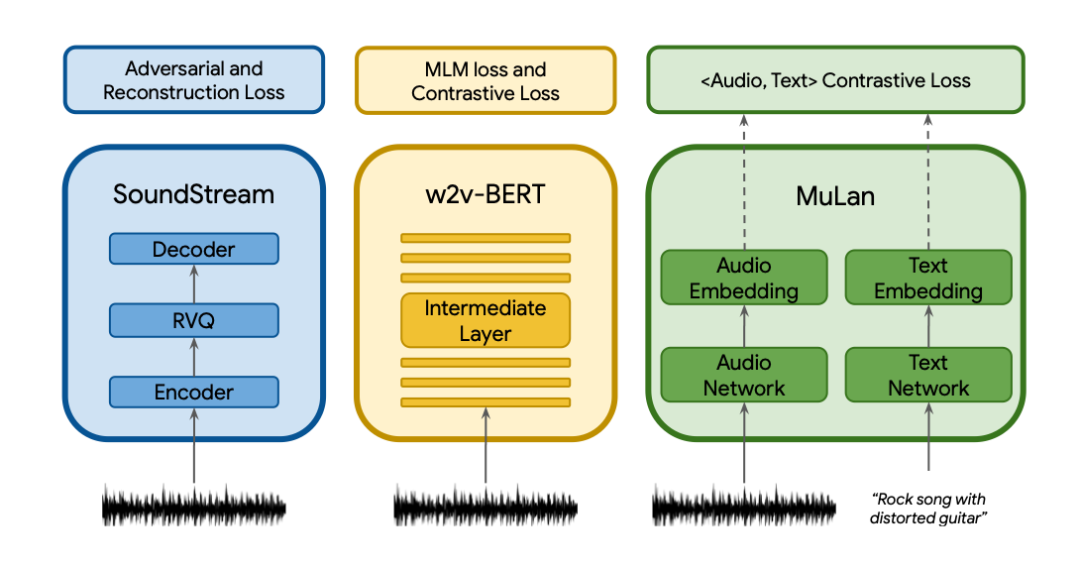
15 Text-to- 文本指令生成音樂
是由谷歌研究院在近日發(fā)布的文本生成音樂模型,只發(fā)布了論文與數(shù)據(jù)集,沒有開源。模型可以從文本描述例如 "平靜的小提琴旋律伴著扭曲的吉他旋律"生成高保真的音樂。將文本指示的音樂生成過程描述為一個(gè)層次化的序列到序列的建模任務(wù)。它生成的音樂頻率為,在幾分鐘內(nèi)保持一致。
與之前的模型相比,在音頻質(zhì)量和對(duì)文本描述的遵守方面都更優(yōu)。此外,可以以文本描述的旋律為條件,它可以根據(jù)文本說明中描述的風(fēng)格來轉(zhuǎn)換口哨和哼唱的旋律。為了支持未來的研究,谷歌研究院一并公開發(fā)布了。這是一個(gè)由5.5K音樂-文本對(duì)組成的數(shù)據(jù)集,有人類專家提供的豐富文本描述。
16 別忘記了亞馬遜云的存在
是在亞馬遜云上的一站式大模型開發(fā)平臺(tái),可以提高大模型的開發(fā)效率。在IDC發(fā)布的報(bào)告中, 被列入“領(lǐng)導(dǎo)者”陣營(yíng),并居于圖中最高最遠(yuǎn)的位置。
亞馬遜云科技自研AI芯片可以提供更具性價(jià)比的方案,例如 自研芯片的 EC2 Trn1實(shí)例可節(jié)省高達(dá)50%的訓(xùn)練成本,而Inf2實(shí)例可支持橫向擴(kuò)展分布式推理,方便部署并提升高速推理。
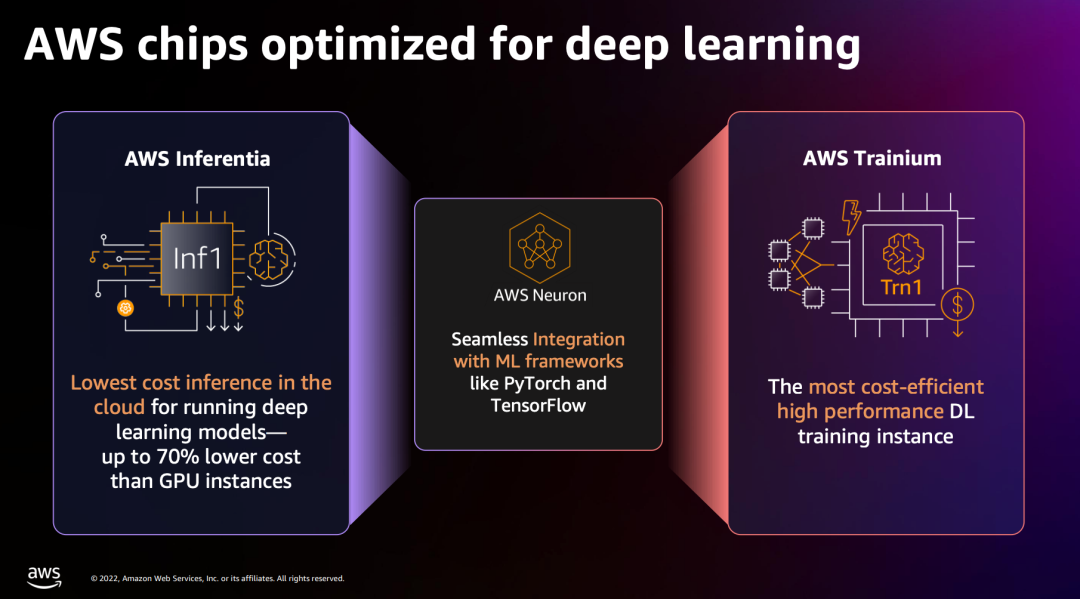
AI選擇AWS作為唯一云服務(wù)提供商,在AWS平臺(tái)上搭建了大規(guī)模訓(xùn)練集群。使用 預(yù)集成的SD2.0預(yù)訓(xùn)練模型和優(yōu)化庫, AI能夠使其模型訓(xùn)練具有更高韌性和性能,訓(xùn)練時(shí)間和成本可減少58%(這是很多錢)。

免責(zé)聲明:本文系轉(zhuǎn)載,版權(quán)歸原作者所有;旨在傳遞信息,不代表本站的觀點(diǎn)和立場(chǎng)和對(duì)其真實(shí)性負(fù)責(zé)。如需轉(zhuǎn)載,請(qǐng)聯(lián)系原作者。如果來源標(biāo)注有誤或侵犯了您的合法權(quán)益或者其他問題不想在本站發(fā)布,來信即刪。
聲明:本站所有文章資源內(nèi)容,如無特殊說明或標(biāo)注,均為采集網(wǎng)絡(luò)資源。如若本站內(nèi)容侵犯了原著者的合法權(quán)益,可聯(lián)系本站刪除。