chatgpt識別圖像 由ChatGPT談談下一代多模態模型的雛形
本文約5800字,建議閱讀11分鐘
本文淺談對多模態模型的新的認識。
最近風頭正勁,但只能理解文字或多或少限制其才華的發揮。得益于在NLP和CV領域的大放異彩,多模態近幾年取得了非常大的進步。但之前的工作大多數局限在幾個特定的,比如VQA,ITR,VG等任務上,限制了其應用。
最近, Li大佬掛出了他最新的杰作。讓我對多模態模型有了一些新的認識,希望通過本文分享一下我的想法。由于本身水平有限,加上很長時間沒有過相關領域的論文了,里面大部分的思考可能都是閉門造車,所以不可避免有很多錯誤,歡迎大家指正討論。

,BLIP, 都是 Li [1]大佬的杰作,給了我很大的啟發。去掉了笨重的,BLIP統一了理解與生成,再次刷新了我的認知,感謝大佬!
TL,DR
先一言以蔽之:
實現了開放性的多模態內容理解與生成,讓我們有了更多的想象空間;
從新的視角去看待圖文模態,引入了LLM模型。CV模型是傳感器,負責感知,LLM模型是處理器,負責處理;
相對友好的計算資源,比起動輒幾百張卡的大模型chatgpt識別圖像,BLIP 2 最大的模型也不過16張A100 40G;
傳統圖文任務上性能爆表。
從泰坦尼克號說起
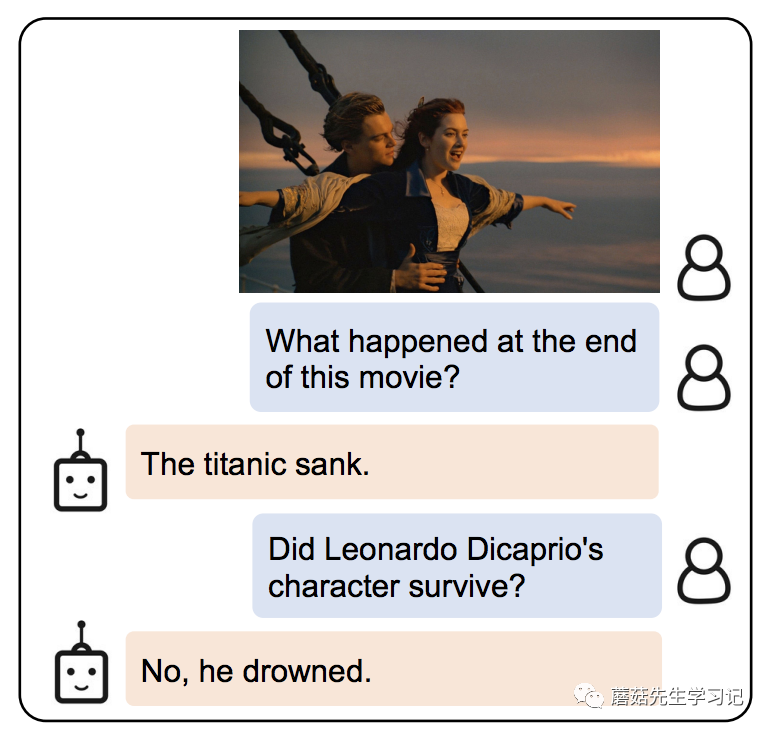
開始前介紹論文前我們先來討論下,實現圖片中的問答,需要什么能力呢?
圖片里發生了什么:一位男士在船頭摟著一位女士。(感知-CV模型的能力)
問題問的什么:電影的結尾是什么?(感知-NLP模型的能力)
圖片和電影有什么關系:這是泰坦尼克號里的經典鏡頭。(對齊融合-多模態模型的能力)
電影的結尾是什么:泰坦尼克號沉沒了。(推理-LLM模型的能力)
對不同模型扮演角色的理解
從上面的問題可以看出,為了解決這個問題,需要幾個模型配合一下。其實自從多模態模型 (特別是圖文多模態模型) 出現,模態之間怎么配合就是個問題。

19年、20年的時候,和采用了-Text對來提升模型對圖片的理解能力。的引入,不可避免的需要一個笨重的檢測器,去檢測各種框,使得圖像模態顯得比較笨重。而且檢測器模型不可避免的會存在漏檢的問題,可以參考后來Open-一些工作,比如ViLD。這一階段,顯然對圖像的理解是多模態的重頭戲,文本更多是輔助圖像任務的理解。

到了21年、22年,去掉檢測器成了主流,ViLT,,VLMo,BLIP 等等都拋棄了檢測器,徹底擺脫了CNN網絡的舒服,全面擁抱,當然這也得益于本身ViT模型在CV領域的大放光彩,讓兩個模態的有機融合成為了可能。在這一階段,文本模態感覺已經可以和圖像模態平起平坐了。從在各項具體下游任務(VQA、VG、ITR)的實際表現上來說,已經比較令人滿意了。但總感覺差點味道,就是復雜推理。比如VQA上的問題,大多數是簡單的邏輯計算或識別,感覺還不夠智能。
那么如何實現更加復雜的推理呢?眾所周知,NLP領域一直領先于CV領域的發展。得益于更豐富的語料庫,NLP領域的已經擁有了一些具有初步推理能力模型的研究,特別是LLM大模型的出現。(今天谷歌剛剛發布了22B的ViT,而在NLP領域這個規模的模型應該已經不算新聞了。)我對于LLM能力有多強的理解,其實也是之后才有明確的感知。
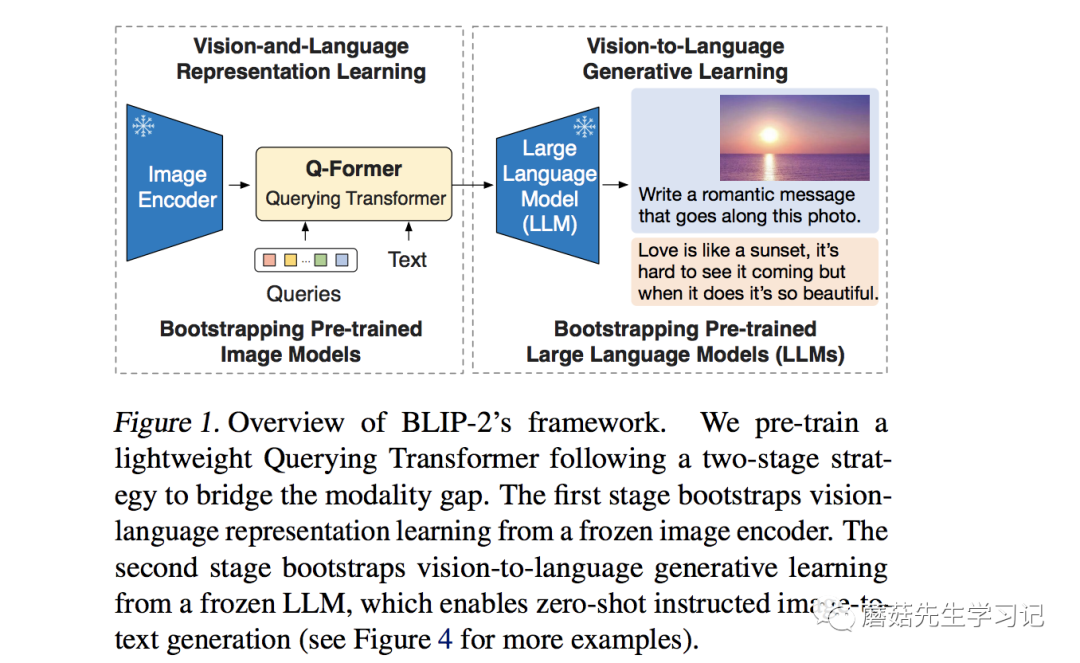
23年1月,出來了,引入了LLM。從圖像上看,大概由這么幾個部分組成,圖像()輸入了圖像編碼器( ),得到的結果與文本(Text)在 Q-(BERT初始化)里進行融合,最后送入 LLM模型。我是學自動化出身的,從自動化的角度看看。
之前的模型大多都關注在了傳感器和融合算法的設計上chatgpt識別圖像,但忽略了處理器的重要作用。BERT模型雖然能理解文本,但卻沒有世界觀的概念,沒有龐大的背景知識庫,只能作一個傳感器。只有LLM模型,才能實現這一角色chatgpt識別圖像,統一起各個模態的信號,從一個宏觀的角度去看待這個問題。這里引用一段原文中的話。
by LLMs (e.g. OPT ( et al., 2022), ( et al., 2022)), BLIP-2 can be to zero-shot -to-text that , such as , , etc.
目前看,或許LLM就是下一代多模態模型的關鍵一環。
言歸正傳,我們開始介紹論文。
如何統一多模態的表征
LLM本質上是個語言模型,自然無法直接接受其他模態的信息。所以如何把各個模態的信息,統一到LLM能理解的特征空間,就是第一步要解決的問題。為此,作者提出了Q-。
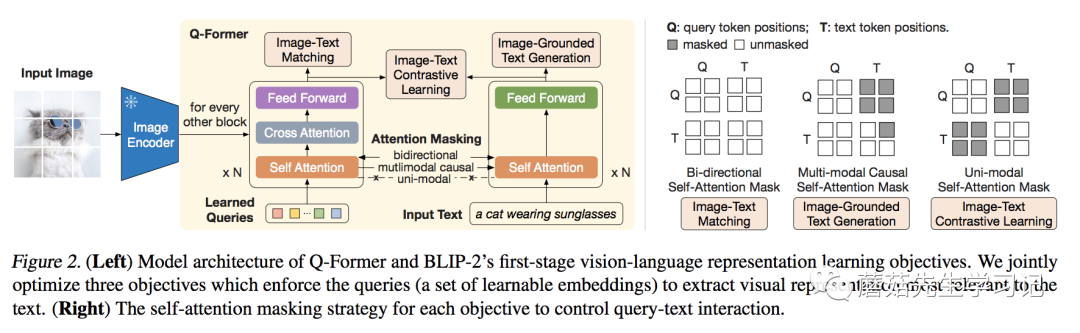
為了融合特征,那架構是最合適不過的了。熟悉或者BLIP的同學或許發現,Q-的結構和其實很像,如果看代碼[3]的話,可以發現就是在基礎上改的。
相較于,最大的不同,就是 的引入。可以看到這些通過-與圖像的特征交互,通過Self-與文本的特征交互。這樣做的好處有兩個:(1) 這些是基于兩種模態信息得到的;(2) 無論多大的視覺,最后都是長度的特征輸出,大大降低了計算量。比如在實際實驗中,ViT-L/14的模型的輸出的特征是的大小,最后也是的特征。
這里其實有點疑問,也歡迎大家討論。論文里是這樣講的:
This with our pre- into the to that is most to the text.?
作者通過Q-強制讓提取文本相關的特征,但如果在推理時沒有文本先驗,那什么樣的特征算是相關的呢?
針對Q-的三個訓練任務分別是 -Text (ITC),- Text (ITG),-Text (ITM)。其中 ITC 和 ITM 任務,與中的實現類似,只不過圖像特征改為了的特征,具體可以參考代碼實現(ITC[5]和ITM[6])。這里比較特別的是ITG任務,與中的MLM不同,這里改成了生成整句Text的任務,類似,具體代碼實現ITG[7]。實際上,這幾個任務都是以特征和文本特征作為輸入得到的,只不過有不同的Mask組合,具體可以參考上圖中的右圖。
第一階段,對于模型的訓練,就是由以上三個任務組成,通過這幾個任務,實現了對于特征的提取與融合。但現在模型還沒見過LLM。我們現在用傳感器完成了數據的提取與融合,下一步,我們得把數據轉換成處理器能識別的格式。
變成LLM認識的樣子
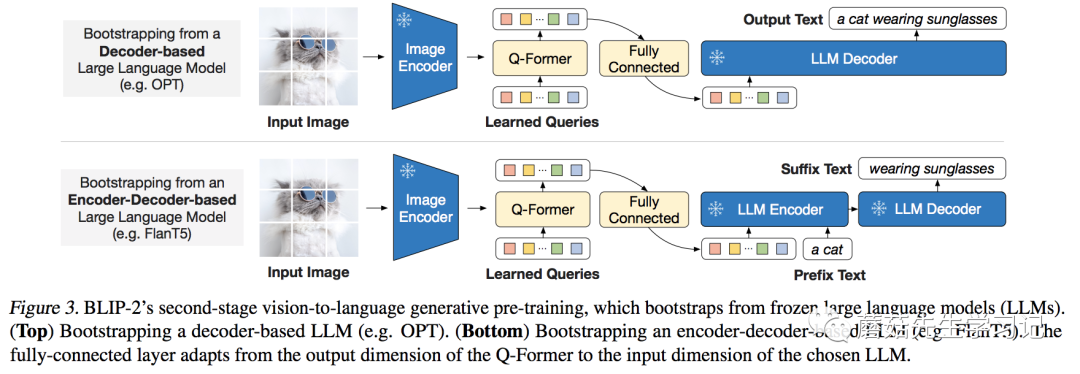
通過第一階段的訓練,已經濃縮了圖片的精華,現在要做的,就是把變成LLM認識的樣子。
為什么不讓LLM認識,而讓變成LLM認識呢?這里的原因有兩:(1)LLM模型的訓練代價有點大;(2)從 的觀點來看,目前多模態的數據量不足以保證LLM訓練的更好,反而可能會讓其喪失泛化性。如果不能讓模型適應任務,那就讓任務來適應模型。
這里作者針對兩類不同LLM設計了不同的任務:
類型的LLM(如OPT):以做輸入,文本做目標;
-類型的LLM(如):以和一句話的前半段做輸入,以后半段做目標;
為了適合各模型不同的維度,作者引入了一個FC層做維度變換。
至此,模型兩階段的訓練方法就介紹完了。
訓練細節
作為圖文預訓練的工作,工程問題往往是關鍵。的訓練過程主要由以下幾個值得關注的點:
訓練數據方面:包含常見的 COCO,VG,SBU,CC3M, 以及 115M的中的圖片。采用了BLIP中的方法來訓練數據。
CV模型:選擇了CLIP的ViT-L/14和ViT-G/14,特別的是,作者采用倒數第二層的特征作為輸出。
LLM模型:選擇了OPT和的一些不同規模的模型。
訓練時,CV模型和LLM都是凍結的狀態,并且參數都轉為了FP16。這使得模型的計算量大幅度降低。主要訓練的基于BERT-base初始化的Q-只有188M的參數量。
最大的模型,ViT-G/14和-XXL,只需要16卡A100 40G,訓練6+3天就可以完成。
所有的圖片都被縮放到的大小。
實驗部分
作者首先用了整整一頁的篇幅,為我們展示了的 zero-shot -to-text 能力。這里暫且按下不表,到后面一起討論。我們先看看在傳統的一些圖文任務上的效果。
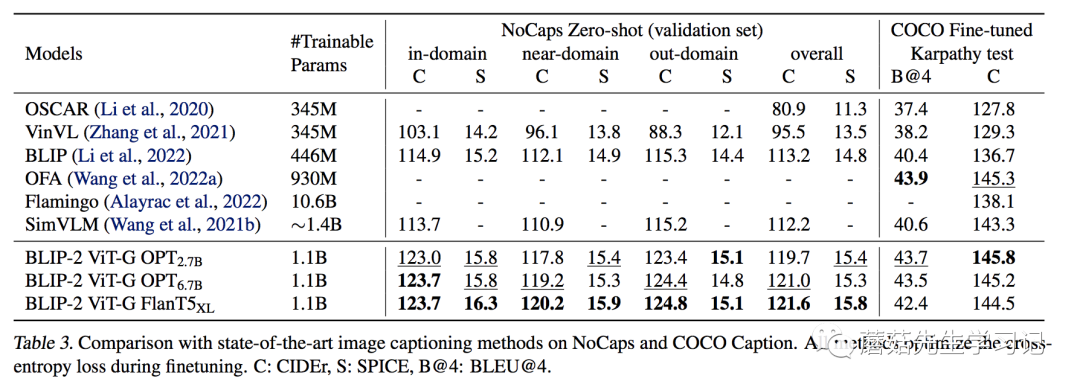
作者用圖片配合文字 “a of”作為模型的輸入。訓練過程中凍結LLM,訓練Q-和CV模型。可以看到,在域內數據集(COCO)上,其表現并沒有非常亮眼,但在域外數據集上,顯示出了強大的泛化能力,相較之前的模型有明顯的提升。


訓練的參數和IC任務一致,主要是Q-和ViT。不同的是,Q-和LLM都有作為文本輸入。Q-的文本輸入,保證了提取到的特征更加的精煉。
-Text
ITR任務,作者只采用了第一階段的Q-和ViT來做,沒有引入LLM。具體的做法與類似,先通過ITC任務算出點積相似度,再取Topk的匹配對,作ITM任務,得到最后的 。上再次刷新了SOTA,特別是I2T,基本飽和了。
Zero-shot -to-Text
我覺得這個能力才是最亮眼的地方。文章中是這樣說的:
of zero-shot -to-text a BLIP-2 w/ ViT-G and , it wide of , , , , -to-text , etc.
首先我們來看看對信息的檢索能力,下面幾個例子都是對圖片中物體的背景知識提問,可以看到,模型都給出了相應的答案。這里體現的實際上是LLM強大的背景知識庫。圖中有什么(ViT)+問的是什么(Q-,LLM)+找答案(LLM)。

下面的幾個問題,都是要求模型對圖片的內容進行進一步的推理。比如圖二,需要建立對男人驚訝和雞之間的因果聯系。
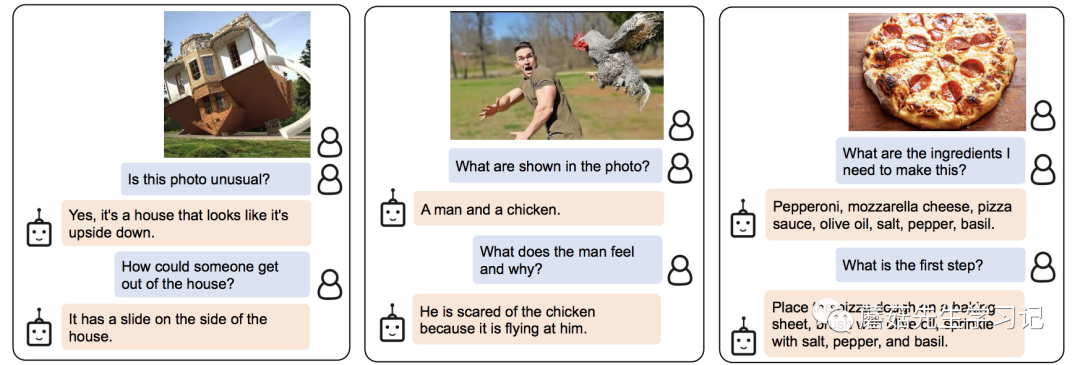
最后的幾個問題是開放性的生成問題。需要模型有一定的長文本生成能力。

為了進一步探索模型的效果,我也自己測試了一些Demo,這里采用的是ViT-G和的模型組合, Face 上提供的CKPT加起來有50G左右了,作為一個平時接觸CV多一點的人來看,是想當炸裂的,一般我模型的CKPT和最后那個零頭差不多。
先介紹一下測試的輸入格式,這里主要參考[8]
我測試了如下形式的輸入樣例,其中比較特別的是 ,這里除了圖片中的信息,我還會給出一段文本中的信息,希望模型通過綜合兩個模態的信息給出答案。
下面是一些測試樣例以及有趣的發現。粗體為模型的輸出結果。
樣例: 380

首先,我們問幾個簡單的問題
Q: What type of is this?
A: a a380
Q: What are the of this type of ?
A: the a380 is the .
可以看到基本給出了正確的回答,但當我詢問飛機載客量時,模型確依然給出了380,推測可能是這個飛機和380這個數字的聯系比較緊密。
Q: How many can this ?
?A: 380
?
于是,同樣的問題,我們給出一點文字上的提示,這里摘取了一段Wiki上的介紹送入模型。
C: The A380 is a wide-body that was and by . It is the 's and only full- -deck jet . in 1988, and the was in 1990 to the of the 747 in the long-haul . The full- -deck has a for 525 , with a for 853 .
Q: How many can the in this ?
A: 853
這時,我們可以看到,模型成功的給出了回答。也就是說,模型有聯合兩個模態信息聯合推理的能力。如果我們使點壞呢,比如給出錯誤的。
C: The A350 is a long-, wide-body twin- jet and by .
Q: What type of is this ?
A: a350
可以看到,模型輸出了錯誤的答案。可能由于本身LLM對文字更加關注,而且的概念可能對他來說并不熟悉,在他看來,32個只不過是帶信息的Word 。
樣例:交通標志

在這個樣例中,我們直接讓模型自己生成個問題。
Q: Give me the .
A: What is the on the road?
接著,我們問問看,模型自己知道答案么?
Q: What is the on the road?
A: 40 mph.
可以看到,模型準確地給出了限速。接著我們讓他做一些簡單邏輯判斷。
Q: Can I 70 mph here?
A: No.
Q: Can I 30 mph here?
A: Yes.
模型竟然都能夠正確的給出答案。最后,來個OCR的任務,讓模型輸出牌子上寫了什么。
Q: What is on this sign?
A: 40.
模型同樣也給出了正確的答案。可以看到,模型對于邏輯判斷和圖片中文字的識別,都有一定的基礎。
樣例:表格

這里先用文章中自己的表格做測試。
Q: What is the name of the ?
A: a of the mri and ct .
Emmm,屬于是自家人不認自家人了。問問他認識自己不?
Q: Do you know ?
A: is a that in is by the gene.
好吧,不認識。接著又有一些問題,模型的回答也不是很好。
Q: in the best?
A: dcm vs dcm vs dcm vs dcm vs dcm vs dcm.
Q: How many does have?
A: has a of ten .
原因的話,其實比較好理解,表格的圖片相對于自然圖像的Gap較大,模型本身可能缺乏相應的訓練數據;其次,雖然32的使得信息變得精煉,但也使得模型的表達能力有了瓶頸,加上的大小,這種小文字的識別其實是比較困難的。我們看下個例子。
樣例:圖表1
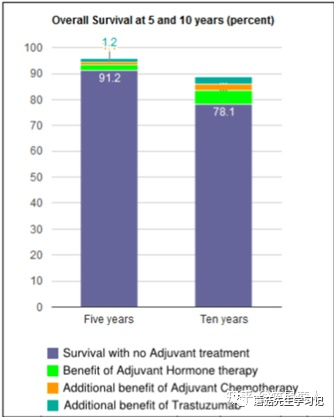
我們讓模型自己問個問題。
Q: Give me the
A: What is the of for with no ?
可以看到,模型提問的大致方向是可以的,比如存活率。但是圖表中的 卻被識別成了 。這說明,模型有一定的OCR能力,但不多。尤其是對于這種比較小又不常見的文字,很容易識別錯誤。
樣例:圖表2
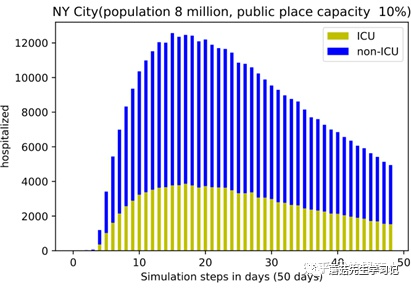
同樣,先讓模型自己問個問題。
C: : Fig. 3. The and ICU ? from our .
Q: Give me the
A: What is the of the city?
自問自答一下。
C: : Fig. 3. The and ICU ? from our .
Q: What is the of the city?
A: NYC 8 .
從這里不難看出,模型其實對于常見的單詞,即使圖片比較小也能夠很好地識別到。最后來個最難的。
Q: On day 20, how many were ?
A: 200, 000.
這個問題的要求其實挺高,需要模型根據坐標去推斷數值,不出意外的回答錯誤了。
首先,不可否認的是,這篇工作確實讓我們的想象空間更多了,尤其是 Zero-shot -to-Text 的能力,我覺得肯定還有沒有發現的潛在能力。但我們從測試樣例中也看到,模型還存在一些問題。在文章中,作者也給出了一些Bad Case,比如錯誤的建立聯系,錯誤的推斷依據以及過時的知識庫。

作者在文中對自己模型的不足主要解釋為,首先,
, our with BLIP-2do not an VQA when the LLM with in- VQA .We the lack of in- to our , only a -text pair per .
由于圖文數據集大多數是一對一的匹配,所以很難讓模型建立上下文的聯系。
其次,
BLIP-2's -to-text have due to from the LLM, the path, or not up-to-date new .
這個主要是由于LLM模型本身局限決定的。
除了作者提到的幾點,我覺得一下幾點也是可以探索的:
細粒度的識別,由于圖像的信息都濃縮在了32個中,所以能否識別細粒度信息以及圖像中重要的位置信息就成了疑問;
更多的任務,強大zero-shot能力,能不能應用在更多的任務上,多模態的類似VG,單模態的類似。
當然從傳感器與處理器的角度去看,其他模態(比如)也可以拿個傳感器去測,然后送給處理器分析分析hhh
當然,的能力應該還遠遠沒有被挖掘完,等有新的認識了再分享。
參考
[1] Li主頁:
/site//
[2] 論文鏈接:
[3] 代碼倉庫:
[4] HF上的Demo:
[5] ITC代碼:
#L125
[6] ITM代碼:
#L160
[7] ITG代碼:
#L228
[8] :/-: This I made with the by .
免責聲明:本文系轉載,版權歸原作者所有;旨在傳遞信息,不代表本站的觀點和立場和對其真實性負責。如需轉載,請聯系原作者。如果來源標注有誤或侵犯了您的合法權益或者其他問題不想在本站發布,來信即刪。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。