構建chatgpt數據 從大數據的角度看ChatGPT

引起業界的極大關注,作為大數據技術研究人員,更希望從大數據的角度來看待,畢竟在大數據驅動的人工智能時代,此類大模型沒有大數據,就如同機器沒有電一樣。
根據的解釋, 是的兄弟模型,兩者非常相似,不同之處僅在于訓練模型的數據量。目前關于的技術文檔比多一些,因此,我們從文檔中關于數據部分的描述可以看看。關于、和GPT-3的關系及技術差別見本文最后,這里先將模型的訓練數據,包括互聯網大數據和對話相關的數據集。下面分別介紹數據集、處理方法、以及爬蟲作用。
互聯網大數據及處理
模型最主要的數據是互聯網大數據,是來 的部分數據,共1萬億個詞匯、570G,覆蓋了2016-2019年間的互聯網文本數據,包括HTML、word、pdf等等各類型。這些數據可通過亞馬遜的云計算服務進行訪問,據說只需25美元就可以設置一個亞馬遜帳戶獲取這些抓取數據。從頁面語言來看構建chatgpt數據,最多的是英文,共有15億個頁面(根據2022年某個月抓取的頁面統計)。截至2021年12月,我國網頁數量為3350億個,2021年比2020年增加195億個頁面,每個月新增加16.2億構建chatgpt數據,因此 收錄的中文頁面大概不超過總數的10%。除此以外,還有來自英文和基于互聯網的兩個圖書庫(具體未知)。
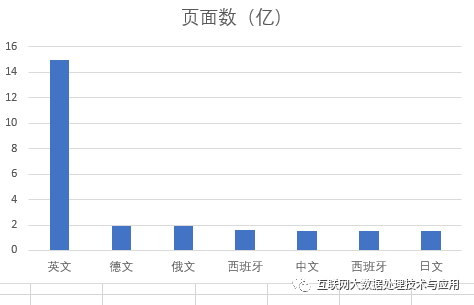
從這里,我們也可以看出,由于訓練數據將近50%是英文,在經過多層模型學習后,最終也可能學習到一些所謂“價值觀”的高層特征,因此在新的AI時代 文化安全更加富有挑戰性。
對數據集進行了兩個主要的處理,即 低質量頁面過濾、 頁面相似性去重,以避免過擬合。這也是采用互聯網大數據進行機器學習不可少的步驟。頁面質量過濾時,采用的是機器學習方法。選擇作為高質量文檔類,訓練一個文檔質量分類器(邏輯回歸分類器+的標準切分和作為特征表示),訓練好的分類器用于對的文檔進行質量過濾。頁面去重時,使用和該質量分類器相同的文檔特征表示,利用的進行文檔相似性計算,大概排除了10%的相似頁面,有利于減小相似文檔導致的模型過擬合,以及降低模型訓練復雜度。
支持對話的相關數據集
GPT-3有很強的上下文表示能力,但缺乏用戶交互行為的學習。模型引入了強化學習和監督學習來 理解用戶意圖,正是由于有了很好的意圖理解能力,我們和的對話才能顯得自如。相應的支持訓練數據主要有:
(1) SFT數據集:由標注人員對用戶輸入提示行為進行標注,共13K個訓練提示,該數據集用于微調GPT-3,采用監督學習方法 fine- (SFT)。
(2) RM數據集:標注者對給定輸入的預期輸出進行排序,共33K個記錄,數據集用于訓練獎勵模型 (RM)以預測人類想要的輸出。
(3) PPO數據集:沒有標注,用于RLHF(g from ,從人類反饋中獲得的強化學習)微調。
正是由于這些數據集的引入,使得在多輪會話中,能夠有效地理解我們的意圖,這點倒 是AI一個很大的進步。這里我們也可以看到在AI時代標注之類的勞動密集型工作留給人類來做,按此趨勢人類大腦退化不是沒有可能的,哈哈~
、GPT-2、關系介紹
是于2022年初發布的語言模型,可以看作是一個經過微調的新版本GPT-3構建chatgpt數據,它的新在于可以盡量減少有害的、不真實的和有偏差的輸出。吸取了 的Tay在使用來自 的開放數據進行訓練后出現的種族傾向錯誤。這個是 人工智能安全的視角,在信息化進入智能化后,安全升級為第一要位, 沒有安全也就沒有AI應用,自動駕駛就是很好的例子。當然目前這個架構,還很 容易受到數據投毒攻擊,后續有空我再寫一篇人工智能安全視角下的。
這個模型比GPT-3小了100多倍,僅有13億個參數,比GPT-2還少。與之前各類語言模型不同的是, 是為對話構建的大型語言模型,也可以稱之為對話語言模型吧,因此該模型的設計目標之一是能夠讓模型知道人類的意圖。因此,主要技術是通過結合監督學習+從人類反饋中獲得的強化學習(RLHF,g from ),提高GPT-3的輸出質量。
爬蟲的作用
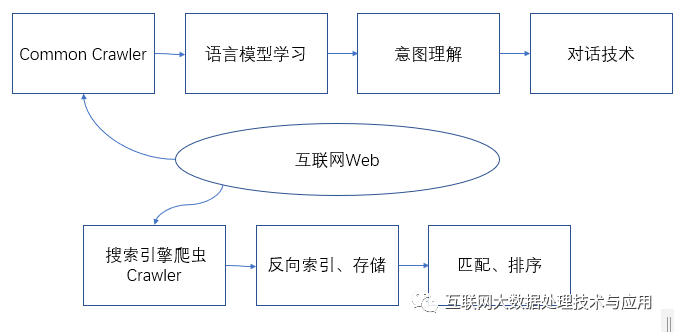
盡管目前還是利用他人爬蟲數據集,但是作為一個獨立成長的AI系統,將來免不了自己采集,否則難于跟上用戶變化。雖然進入了 AIGC時代,但是 UGC仍然長期存在,否組用AIGC去訓練AI,那就相當于自己拉的si自己吃了,最終免不了病態。當然并非否定AIGC,它作為一種輔助數據增強的手段還是非常受到大家的歡迎。
從這個角度看它和搜索引擎有一定相似地方,才會有很多人認為它是搜索引擎的增強或者將來要代替搜索引擎了。搜索引擎只是將爬蟲抓來的頁面提取、解析后進行逆向索引,然后存儲關鍵詞和頁面的對應關系即可為用戶提供匹配服務,而技術手段要更深刻很多了,語義理解、大數據技術、監督學習、強化學習以及意圖理解等等。不過搜索引擎公司所擁有的頁面數據比所使用的大數據集要大很多,將來自己定制一個對話語言模型是很有基礎的,希望不久能出品。
轉載請注明:本文來自互聯網大數據處理技術與應用公眾號。歡迎針對文中提到的一些觀點一起討論,后臺留言。
免責聲明:本文系轉載,版權歸原作者所有;旨在傳遞信息,不代表本站的觀點和立場和對其真實性負責。如需轉載,請聯系原作者。如果來源標注有誤或侵犯了您的合法權益或者其他問題不想在本站發布,來信即刪。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。