《2023 大語言模型綜合能力測評報告》
近日國內與人工智能領域相關的利好政策陸續釋放,中央召開的相關會議強調“未來要重視通用人工智能發展,營造創新生態。”《北京市促進通用人工智能創新發展的若干措施(2023-2025 年)(征求意見稿)》圍繞五大方向提出 21 項具體措施,包括“開展大模型創新算法及關鍵技術研究”,“加強大模型訓練數據采集及治理工具研發”等,同時面向政務服務、醫療、科學研究、金融、自動駕駛、城市治理等領域拓展應用場景,以搶抓大模型發展機遇,推動通用人工智能領域實現創新引領,中國大模型技術產業迎來了一波前所未有的發展契機,百度、阿里、華為等國內眾多企業迅速布局了相關業務,推出自家的人工智能大模型產品。
此外,目前全球整個大模型領域都擁有著較高密度的人才團隊,且有資本加持。在人才方面,從目前公布的部分大模型研發團隊背景可以看出, 團隊成員均來自國際頂級高校或擁有頂級科研經驗;在資本方面,以 和 舉例,這兩家 2022 年在大模型技術方面的資本性支出分別達 583 億美元和 315 億美元,并仍然呈現上漲趨勢,就 最新披露數據,其訓練參數規模 1750 億的大模型, 理想訓練費用超過 900 萬美元。
當一個領域有高密度的資本和人才團隊,那意味著這個領域將有更快的發展。很多人覺得, 這一現象級產品橫空出世,拉開了大語言模型技術蓬勃發展的序幕。但實際上,自 2017 年大語言模型誕生,、微軟、谷歌、、百度、華為等科技巨頭在大語言模型領域的探索持續不斷, 只是將大語言模型技術推進至了爆發階段,當下大模型產品格局更是呈現出了新形勢——國外基礎模型積累深厚,國內應用側優先發力。
為此 研究中心基于桌面研究、專家訪談、科學分析三個研究方法,查找了大量文獻及資料,采訪了 10+ 位領域內的技術專家,同時圍繞語言模型準確性、數據基礎、模型和算法的能力、安全和隱私四個大維度,拆分出語義理解、語法結構、知識問答、邏輯推理、代碼能力、上下文理解、語境感知、多語言能力、多模態能力、數據基礎、模型和算法的能力、安全和隱私 12 個細分維度,分別對 gpt-3.5-、-、Sage gpt-3.5-、天工 3.5、文心一言 V2.0.1、通義千問 V1.0.1、訊飛星火認知大模型、Moss-16B、-6B、-13B 進行了超過 3000+ 道題的評測,根據測評結果發布了《大語言模型綜合能力測評報告 2023》(下文簡稱《報告》)。
為了保證報告的客觀性、公正性及計算結果的準確性, 研究中心根據樣本制造了一套科學的計算方法——通過實際測試獲得各模型對 300 道題目的答案,針對答案進行評分,正確答案獲得 2 分,部分正確的答案獲得 1 分,完全錯誤的獲得 0 分,模型表示不會做的獲得 -1 分。計算公式為“某模型在某細分類別題目得分率 = 模型得分 / 模型總分”。舉個例子,A 大模型在 7 道題目的類別中總得分為 10,該類題目可獲得的總得分為 7*2=14,則 A 大模型在這個題目類別的得分為 10/14=71.43%。
基于以上評測方法,報告主要得出了許多值得大家關注的結論,希望下文的核心結論解讀可以為各位的未來大語言模型技術具體實踐和探索提供方向。
一、百億參數規模是大模型訓練的“入場券”,大模型技術革命已經開始
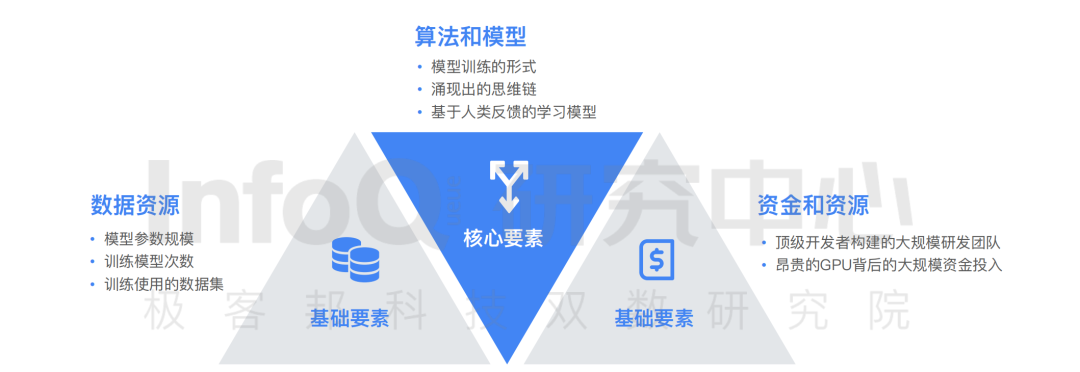
企業對于大模型產品研發需要同時具備三大要素,分別為數據資源要素、算法和模型要素、資金和資源要素。通過對目前市場中的產品特征進行分析, 研究中心發現數據資源、資金和資源兩要素為大模型研發的基礎要素,算法和模型是目前區分大語言模型研發能力的核心要素。算法和模型影響的的模型豐富度、模型準確性、能力涌現等都成為評價大語言模型優劣的核心指標。此處需要說明的是,雖然數據、資金資源為大語言模型研發設置了高門檻, 但對于實力雄厚的大型企業仍然是挑戰較小的。
仔細研究大模型產品的核心要素會發現,大模型訓練需要“足夠大”,百億參數規模是“入場券”。就 GPT-3 和 的數據顯示,在模型參數規模處于 100 到 680 億這個區間時,大模型的很多能力(如計算能力)幾乎為零。同時,大量計算觸發了“煉丹機制”,根據 論文里的附錄章節顯示,一次迭代的計算量約為 4.5 ,而完整訓練需要 9500 次迭代,完整訓練的計算量即為 430 (相當于單片 A100 跑 43.3 年的計算量)。
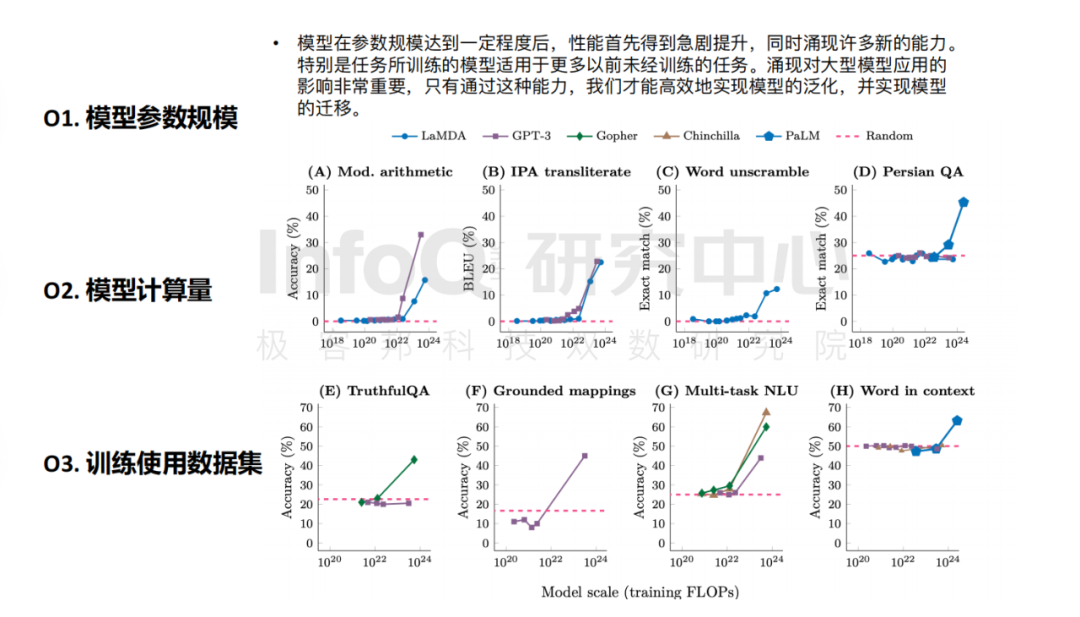
數據來源: of with GPT-4
縱觀全球大模型訓練參數規模的數量級,根據民生證券研究所和 wiki 百科資料顯示,國際領先的大模型 GPT-4 的推測參數量級可達 5 萬億以上,國內部分大模型規模大于 100 億。其中,百度研發的 和華為研發的盤古目前是有數據的國內大模型參數規模的領先者。

研究中心對各家的大語言模型進行了綜合測試后也發現,國外的 各項能力確實很抗打,位居第一位。令人驚喜的是,百度的文心一言闖進了前三名,位居第二,而且值得一提的是,其綜合得分僅落后 2.15,遠超第三名 。
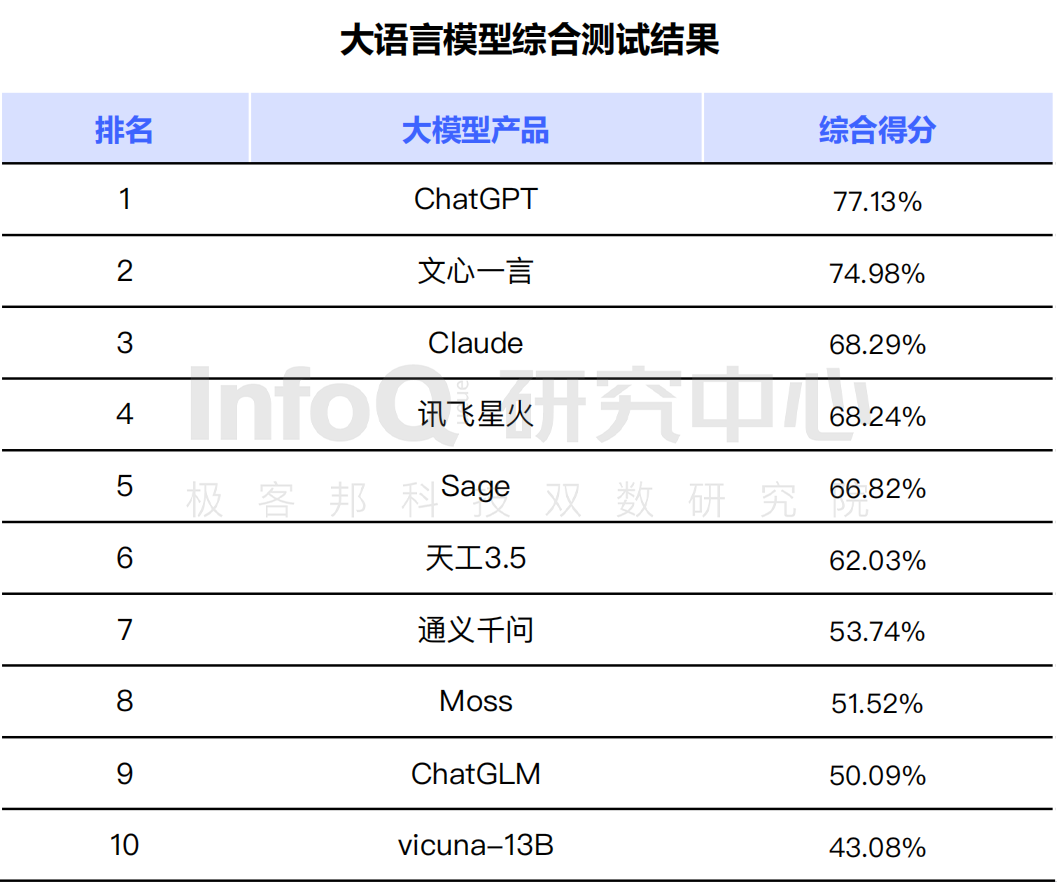
數據說明:測評結果僅基于上文所列模型,測評截止時間為 2023 年 5 月 25 日
在整個研究過程中, 研究中心發現,算法和訓練模型水平主導大語言模型的能力表現。從基礎模型到訓練方式的工程化,再到具體的模型訓練技術,目前賽道中的所有廠商,每一個環節模型選型的差異造就了大語言模型的最終能力表現的差異。

可能各個廠商的產品能力有所差異,但是因為參與到大模型技術建設的玩家足夠多,他們對技術持續的探索,讓我們看到了大模型技術革命成功的希望。在大模型產品百花齊放的當下,大語言模型將計算機能力從“搜索”拓展到了“認知 & 學習”到“行動 & 解決方案”層面,大語言模型的核心能力已經呈現出金字塔結構。

二、“寫作能力”和“語句理解能力”是大語言模型目前擅長能力的 Top2
據 研究中心的測評結果顯示,安全和隱私問題是大語言模型研發的共識和底線,位居能力評分第一位。大語言模型的基礎能力整體表現均排名更為靠前,邏輯推理相關的編程、推理和上下文理解目前整體表現仍有較大的提升空間;多模態仍然是少數大語言模型的獨特優勢。
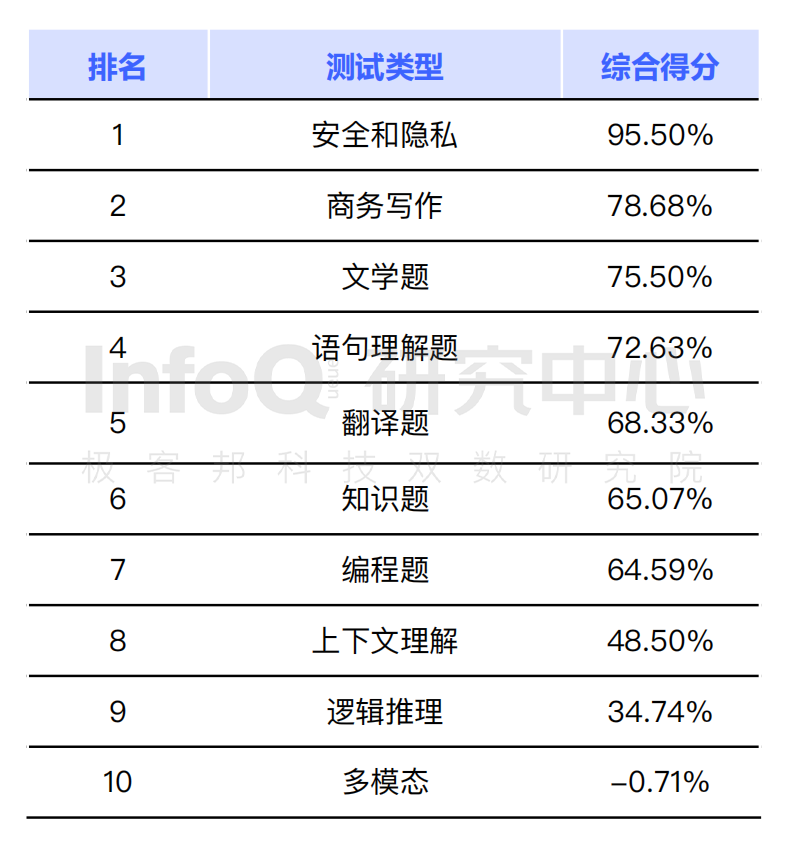
在基礎能力層面,大語言模型展現出了優秀的中文創意寫作能力。在六個寫作細分題目分類中, 大語言模型表現均較為突出,其中訪談提綱和郵件寫作都獲得了接近滿分的成績,而比較之下視頻腳本的寫作仍然是大語言模型產品較不熟悉的領域,細分題目類別得分僅為 75%。
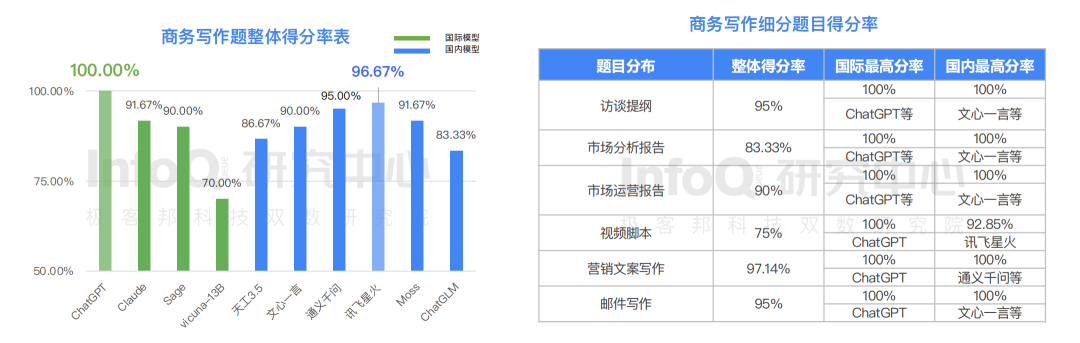
關于文學題,隨著寫作難度的升高,大語言模型表現的能力水平遞減。其中表現最好的板塊為簡單寫作題,得分為 91%;對聯題雖然很多模型表現較好,但是有?些模型對對聯回答表現欠佳, 整體得分最低為 55%。
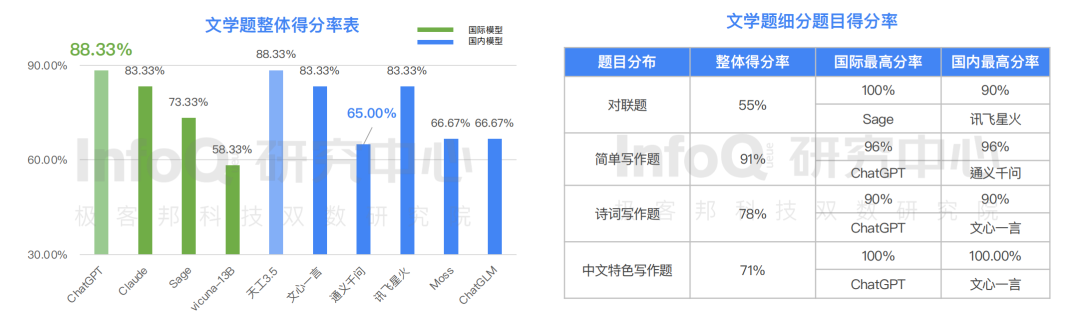
然而,在語義理解方面,目前的大語言模型就沒有那么“靈”了。在方言理解、關鍵詞提煉、語義相似判斷、“怎么辦”4 個題目分類中, 大語言模型呈現很大的差異化分布, “怎么辦”題獲得最高分 92.5%,中文方言理解題難倒了大語言模型,整體準確率僅為 40%。
研究中心的報告顯示,就中文知識這一類題目而言,國內模型表現明顯優于國際模型。在十個模型中知識得分最高的為文心一言,得分 73.33%,得分第二的為 ,得分為 72.67%。除 IT 知識問答題目外,其他八個題目分類中國內的大模型產品在中文知識環境中會的問答表現整體接近或優于國際大模型產品。
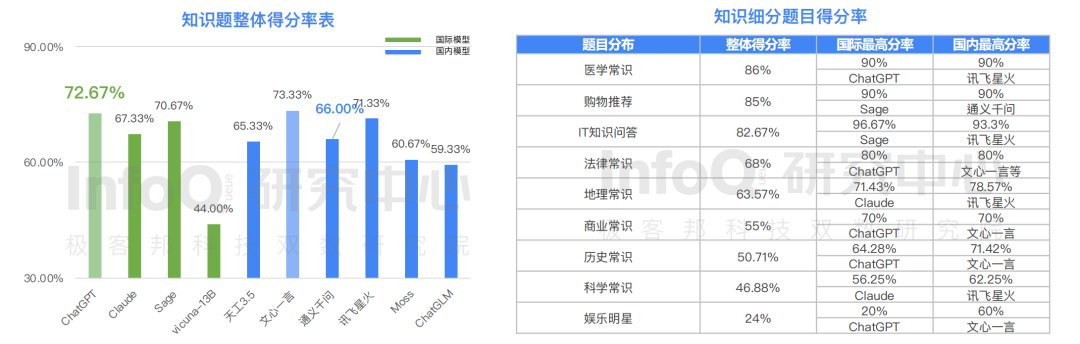
事實上,無論是中文創意寫作,還是語義理解、中文知識問答,這些題目都主要反應的是大語言模型產品對文字的基礎認知和學習能力,而我們從測評結果中清晰的看到,百度文心一言各方面數據表現優異,各項能力評分都位居 Top2。然而,我們看到的其實不僅是文心一言的技術能力,我們更多看到的是國內大語言模型的強勢技術突破和顯著進步。
三、國內產品在跨語言翻譯中仍有較大提升空間,邏輯推理能力整體挑戰較大
隨著近幾年,國家和國內各廠商在人工智能領域的投入逐年增大,我們看到了國內大語言模型的飛速進步,技術成果使我們喜悅,但是當我們更客觀地去看大語言模型技術的發展,我們會發現我們在一些方面和國際水平相比還有許多提升空間。
比如我們從 研究中心發布的《報告》就可以得知,國外產品編程能力顯著高于國內產品,在十個模型中編程得分最高的為 ,得分 73.47%,國內產品表現最好的文心一言,得分 68.37%,與 還存在一定的距離。在四個題目分類中, 相關題目國外產品明顯超越國內產品,但令人驚喜的是,在“代碼自動補全類”題目中,國內產品文心一言已經超越國外產品,這說明國內產品超越國際水平僅是時間問題。
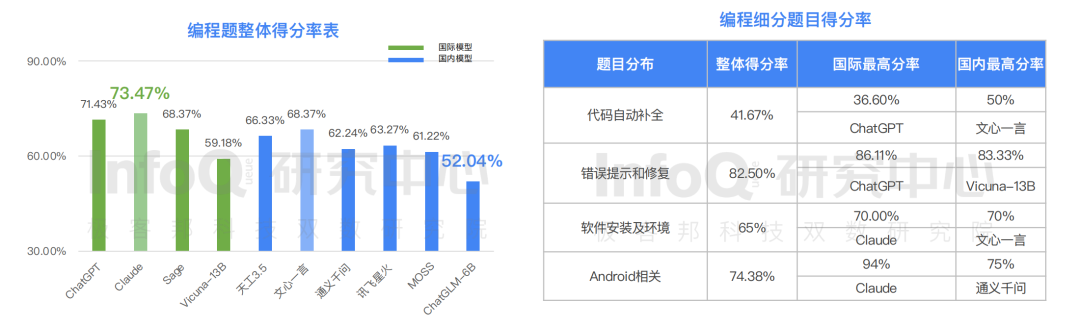
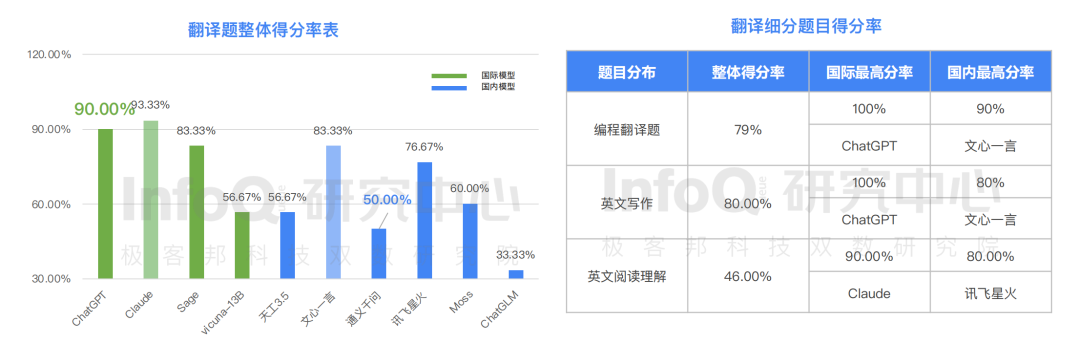
此外,在十個模型中知識得分最高者也是 ,得分 93.33%,國內大語言模型得分最高的分別為文心一言和天工 3.5,但與國際水平依舊存在差距。要知道,翻譯類題目主要反應大語言模型產品對語言的理解能力,此次 評測的“編程翻譯題”、“英文寫作”、“英文閱讀理解”三個題目分類中,大語言模型呈現很大的差異化分布, 在測評的所有模型中,英文寫作題獲得的最高分 80%,而英文閱讀理解僅獲得得分 46%,這意味著國內產品在跨語言翻譯方面還需要繼續努力迭代。
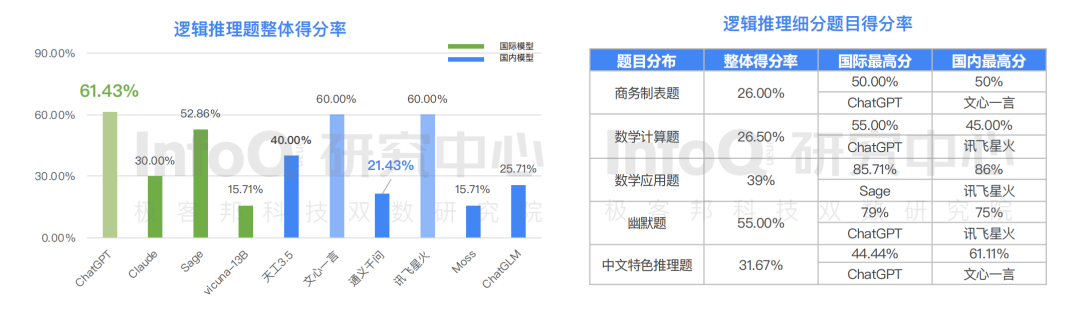
差距猶在,但不必妄自菲薄,大模型技術的技術演進一直在進行著。據《報告》顯示,目前整個大語言模型在邏輯推理能力方面的挑戰都比較大。為了考評大語言模型的理解力和判斷力, 研究中心設置了多個維度的邏輯推理題。在商務制表題、數學計算題、數學應用題、幽默題、中文特色推理題 5 個題目分類中,大語言模型整體得分都低于基礎能力。分析原因, 商務制表題不但需要搜集和識別內容還需要在內容的基礎上做邏輯分類和排序,整體難度較大,邏輯推理能力是未來大語言模型產品的主要進攻方向。
在 研究中心測評的十個模型中,邏輯推理題得分最高的為文心一言和訊飛星火,得分均為 60%,與得分最高的 僅差 1.43%。在部分細分領域,國內產品的表現還是十分優異的,比如在中文特色推理題中,國內模型領先國際模型得分較多, 國內模型對中文內容和邏輯的熟悉應該是該結果的核心原因。
從 研究中心發布的以上測評結果來看國內產品與國外產品的差距,國內大語言模型能力接近 GPT3.5 水平,但是與 GPT4 能力仍存在巨大差距。然而,縱觀整個大語言模型領域,其實我們每個人都可以清晰地發現,大語言模型技術的發展門檻和挑戰還是非常高的,芯片門檻、實踐經驗積累的門檻、數據和語料門檻都需要國內外各大廠商一起努力突破。
從 研究中心的評測結果來看,文心一言的綜合評分已與 所差無幾,在中國最新涌起的互聯網革命浪潮中,文心一言可以稱之為國內最有希望在短期內趕超國際水準的 AIGC 產品。而擁有眾多 AI 專家的文心一言團隊一直保持著兢兢業業地技術探索態度,努力縮小差距中,文心一言的下一次突破已經不遠了,值得我們所有人期待。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。