編程神器Copilot逐字抄襲他人代碼?

編譯|核子可樂、燕珊
“ 向開源軟件注入了自私的基因:我想要什么,你就得給我什么。”
自面世后就飽受爭(zhēng)議的 編程神器最近又遭遇輿論風(fēng)暴。
日前,德州農(nóng)工大學(xué)的一位計(jì)算機(jī)科學(xué)教授 Tim 在推特上發(fā)文稱, 在沒有標(biāo)注來源也沒有 LGPL 許可的情況下,輸出了大量應(yīng)該受版權(quán)保護(hù)的代碼。
Tim 還發(fā)了自己和 在稀疏矩陣轉(zhuǎn)置、稀疏矩陣加法的代碼對(duì)比,并表示兩者幾乎一模一樣,高度雷同。Tim 的推文引發(fā)熱議, 技術(shù)總監(jiān)認(rèn)為這算是 非法洗代碼行為。
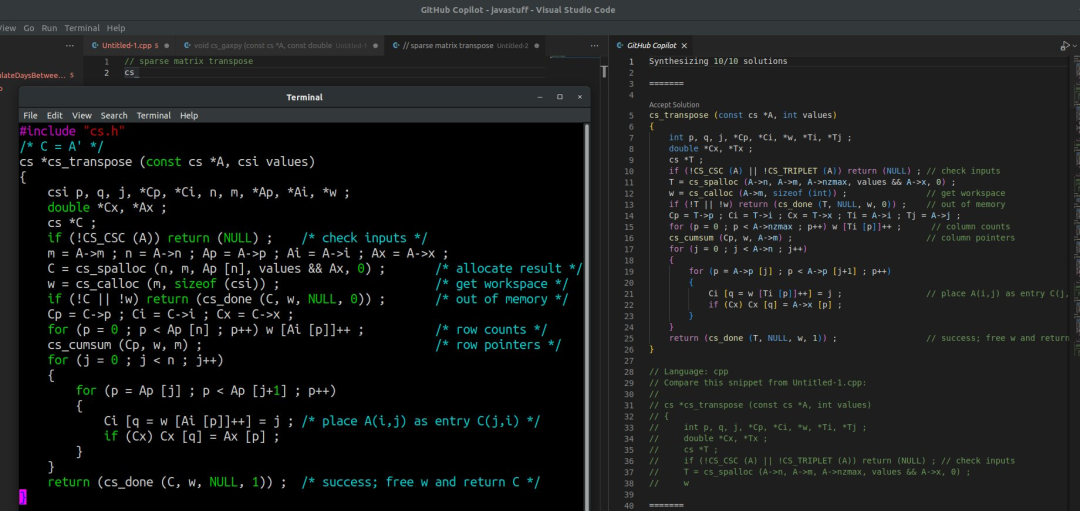
左邊是該名教授的代碼,右邊是 的。
對(duì)此, 的發(fā)明者 Alex 回應(yīng)道,Tim 寫的代碼和 產(chǎn)生的代碼不同,“相似,但不同”。他還提到,如果有人能提供一種方法可以自動(dòng)識(shí)別代碼是由某一方衍生出來的,那就可以申請(qǐng)專利了。
Alex 表示,到目前為止 已被指控了諸多問題,包括剽竊代碼、引入漏洞、代碼不完美、太分散注意力、甚至讓人變笨等等。他強(qiáng)調(diào)道,“我認(rèn)為程序員永遠(yuǎn)不會(huì)被取代。 使人們的工作效率更高。”
起訴
是一款 AI 結(jié)對(duì)編程工具,它的主要定位是提供代碼補(bǔ)全與建議功能。它是 Code 的一個(gè)插件,可根據(jù)當(dāng)前文件的內(nèi)容和當(dāng)前光標(biāo)位置為你自動(dòng)生成代碼。而版權(quán)問題是 從一推出就面臨的挑戰(zhàn),人們質(zhì)疑它在 上發(fā)布的公開代碼上進(jìn)行訓(xùn)練的合法性。
除了 Alex 的“怒懟”,這兩天在 上引起熱議的還有另一篇內(nèi)容《也許你并不在乎 在未經(jīng)許可之下使用你的開源代碼,但如果 要抹除整個(gè)開源社區(qū),你又將作何感想?》,這篇文章來源于一位名叫 的律師,同時(shí)他也是一名程序員。
作為程序員, 從 1998 年起就在專業(yè)參與開源軟件貢獻(xiàn),期間還在 Red Hat 工作過兩年。最近,他又成了 的貢獻(xiàn)者。他寫過文章宣傳 Lisp,也出過介紹編程語言開發(fā)的書,還發(fā)布過不少開源軟件,包括專門用來出版線上書籍的 ,以及他自己在工作中經(jīng)常使用的 AI 軟件。
今年 6 月,在 正式推出的時(shí)候, 寫了一篇關(guān)于 違法問題的文章。而最近, 決定采取下一步行動(dòng),重新激活了自己的加州律師協(xié)會(huì)會(huì)員資格,并和幾位律師發(fā)起了新的項(xiàng)目——針對(duì) 違反對(duì)開源作者及最終用戶的法律義務(wù)一事開展調(diào)查,并考慮進(jìn)行訴訟。
的問題在哪?
首先要說明的是, 跟傳統(tǒng)自動(dòng)補(bǔ)全功能有何區(qū)別?簡(jiǎn)單來講, 由 進(jìn)行支持,而 則是由 構(gòu)建并授權(quán)給微軟的 AI 系統(tǒng)(微軟常被稱為「 的非官方所有者」)。 能根據(jù)用戶輸入的文本 提供建議,而且與只能提示細(xì)節(jié)建議的傳統(tǒng)工具不同, 可以提供更大的代碼塊,包括函數(shù)的完整主體。
但作為底層 AI 系統(tǒng), 是怎么被訓(xùn)練出來的?據(jù) 的介紹, 接受了“數(shù)以千萬計(jì)的公共 repo”的訓(xùn)練,其中當(dāng)然包括 上的代碼。微軟的說辭則較為含糊,只提到“數(shù)十億行公共代碼”。不過 研究員 最近已經(jīng)在播客中證實(shí), 確實(shí)是“由 上的公共 repo 訓(xùn)練而成”。
認(rèn)為,“ 在系統(tǒng)訓(xùn)練與系統(tǒng)使用方面都存在法律問題。”
系統(tǒng)訓(xùn)練
絕大多數(shù)開源軟件包是在授權(quán)許可之下發(fā)布的,在授予用戶一定權(quán)利的同時(shí)也要求其承擔(dān)一定義務(wù)(例如保留源代碼的精確屬性)。而這種授權(quán)的合法實(shí)現(xiàn)方式,就是由軟件作者在代碼中聲明版權(quán)。
因此,要想使用開源軟件,大家就必須做出選擇:
要么遵守許可證所規(guī)定的義務(wù);
要么使用那些屬于許可證例外的代碼(即版權(quán)法所規(guī)定的「合理使用」情形)。
如果微軟和 決定基于各 repo 的開源許可來使用這些訓(xùn)練素材,那就得發(fā)布大量屬性(),這已經(jīng)算是各類開源許可的底線要求。但截至目前,大家都還沒有看到任何屬性聲明。
微軟和 必須找到“合理使用”的理由。 前 CEO Nat 就曾在 的技術(shù)預(yù)覽會(huì)上提到,“在公開數(shù)據(jù)上訓(xùn)練(機(jī)器學(xué)習(xí))系統(tǒng)屬于合理使用的范疇。”
然而,軟件自由保護(hù)組織(SFC)明顯不同意他的觀點(diǎn),并要求微軟方面提供能支持其立場(chǎng)的證據(jù)。保護(hù)組織負(fù)責(zé)人 Kuhn 指出:
我們?cè)?2021 年 6 月私下詢問過 和其他幾位微軟 / 代表,要求他們?yōu)? 的公開法律立場(chǎng)提供可靠的參考依據(jù)……但他們什么都拿不出來。
事實(shí)上,目前全美還沒有哪個(gè)判例能夠直接解決 AI 訓(xùn)練中的“合理使用”問題。另外,所有涉及“合理使用”的案例均權(quán)衡了大量相關(guān)因素。即使法院最終判定某些類型的 AI 訓(xùn)練屬于“合理使用”,也不代表其他類型的訓(xùn)練就能“無腦照辦”。就目前來看,還不知道 和 到底合不合法,微軟和 其實(shí)也說不準(zhǔn)。
系統(tǒng)使用
雖然沒法確定“合理使用”最終要怎么在 AI 訓(xùn)練中落地,但可以想象,其結(jié)果并不會(huì)影響到 用戶。為什么呢?因?yàn)橛脩糁皇窃谑褂? 提供的代碼,而這部分代碼的版權(quán)和許可狀態(tài)同樣模糊不清。
微軟倒是有自己的說法。2021 年,Nat 曾聲稱 的輸出結(jié)果歸屬于操作者,其性質(zhì)與使用編譯器一樣。但 已經(jīng)暗暗給用戶挖好了坑。
微軟將 輸出描述為一系列代碼“建議”,并強(qiáng)調(diào)不會(huì)對(duì)這些建議“主張任何權(quán)利”。但與此同時(shí),微軟也不會(huì)對(duì)由此生成的代碼的正確性、安全性或延伸出的知識(shí)產(chǎn)權(quán)問題做任何保證。所以只要接納了 的建議,那這些問題就都要由用戶自己承擔(dān):
您需要對(duì)自己代碼的安全性和質(zhì)量負(fù)責(zé)。我們建議您在使用由 生成的代碼時(shí),采取與使用其他一切非本人所編寫代碼相同的防范措施,包括嚴(yán)格測(cè)試、IP(知識(shí)產(chǎn)權(quán))掃描和安全漏洞跟蹤。
這樣一來,可能會(huì)產(chǎn)生什么糾葛?用戶控訴,就像上文中 Tim 控訴的這起抄代碼事件。
理論上, 使用他的代碼,當(dāng)然會(huì)產(chǎn)生相應(yīng)的許可遵守義務(wù)。但從 的設(shè)計(jì)來看,用戶完全接觸不到代碼的來源、作者和許可證。
從這個(gè)角度看, 的代碼檢索方法就像一顆煙霧彈,下面掩蓋的是另一種真相: 本身,只是連通海量開源代碼的一套替代接口。只要用上它,用戶可能就需要承擔(dān)起代碼原作者提出的許可義務(wù)。
意識(shí)到這一點(diǎn),Nat 所謂 “就像是編譯器”的說法就會(huì)變得不靠譜。畢竟編譯器只會(huì)改變代碼形式,但絕不會(huì)注入新的知識(shí)產(chǎn)權(quán)屬性。
對(duì)于開源社區(qū)意味著什么?
認(rèn)為,通過將 當(dāng)作海量開源代碼的替代接口,微軟不僅借此切斷了開源作者與用戶之間的法律關(guān)系,甚至建立起新的“圍墻花園”——阻止程序員接觸傳統(tǒng)開源社區(qū),從而消除了他們?yōu)橹暙I(xiàn)的可能性。隨著時(shí)間推移,這勢(shì)必會(huì)讓開源社區(qū)變得愈發(fā)貧乏。
用戶的注意力和參與方向?qū)⒅饾u朝著 轉(zhuǎn)移,最終徹底告別開源項(xiàng)目本身——告別源代碼 repo、告別問題跟蹤器、告別郵件列表、告別討論板。這樣的變化必將給開源帶來痛苦、甚至永遠(yuǎn)無法挽回的損失。
“包括我自己在內(nèi)的開源開發(fā)者之所以提出抗議,所圖的絕不是錢。我們只是不想讓自己的努力貢獻(xiàn)被白白浪費(fèi)掉。開源軟件的核心在于人,在于由人組成的用戶、測(cè)試者和貢獻(xiàn)者社區(qū)。正是因?yàn)橛辛诉@樣的社區(qū),我們才能以超越自身的方式改進(jìn)軟件,讓工作充滿樂趣。” 進(jìn)一步說道, 向開源軟件注入了自私的基因:我想要什么,你就得給我什么。
他最后強(qiáng)調(diào)道:“我們反對(duì)的絕不是 AI 輔助編程工具,而是微軟在 當(dāng)中的種種具體行徑。其實(shí)微軟完全可以把 做得更開發(fā)者友好一些——比如邀請(qǐng)大家自愿參加,或者由編程人員有償對(duì)訓(xùn)練語料庫做出貢獻(xiàn)。但截至目前,口口聲聲自稱熱愛開源的微軟根本沒做過這方面的嘗試。另外,如果大家覺得 效果挺好,那主要也是因?yàn)榈讓娱_源訓(xùn)練數(shù)據(jù)的質(zhì)量過硬。 其實(shí)是在從開源項(xiàng)目那邊吞噬能量,而一旦開源活力枯竭, 也將失去發(fā)展的依憑。”
參考鏈接:
聲明:本站所有文章資源內(nèi)容,如無特殊說明或標(biāo)注,均為采集網(wǎng)絡(luò)資源。如若本站內(nèi)容侵犯了原著者的合法權(quán)益,可聯(lián)系本站刪除。